Denoising Diffusion Probabilistic Models
生成步骤
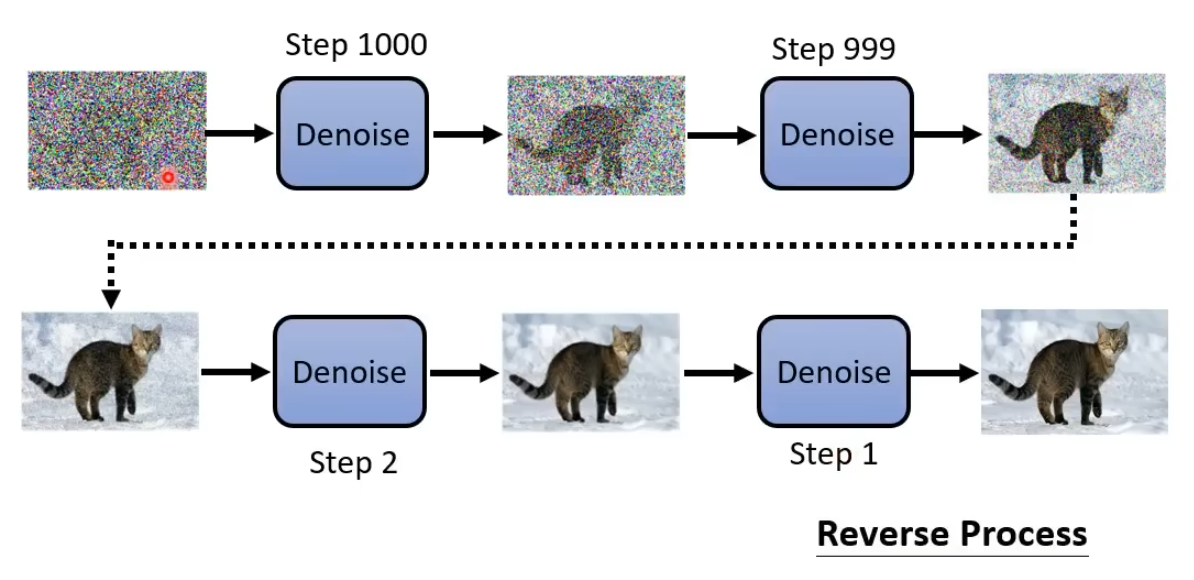
图像生成在SD中是Reverse Process.
Reverse Process
- Sample一个高斯噪声图片
- 使用
Denoise模块去噪 - 重复
Denoise直到达到Step=0
雕像其实在大理石里面,我只是把不需要的部分拿掉了而已。---米开朗琪罗
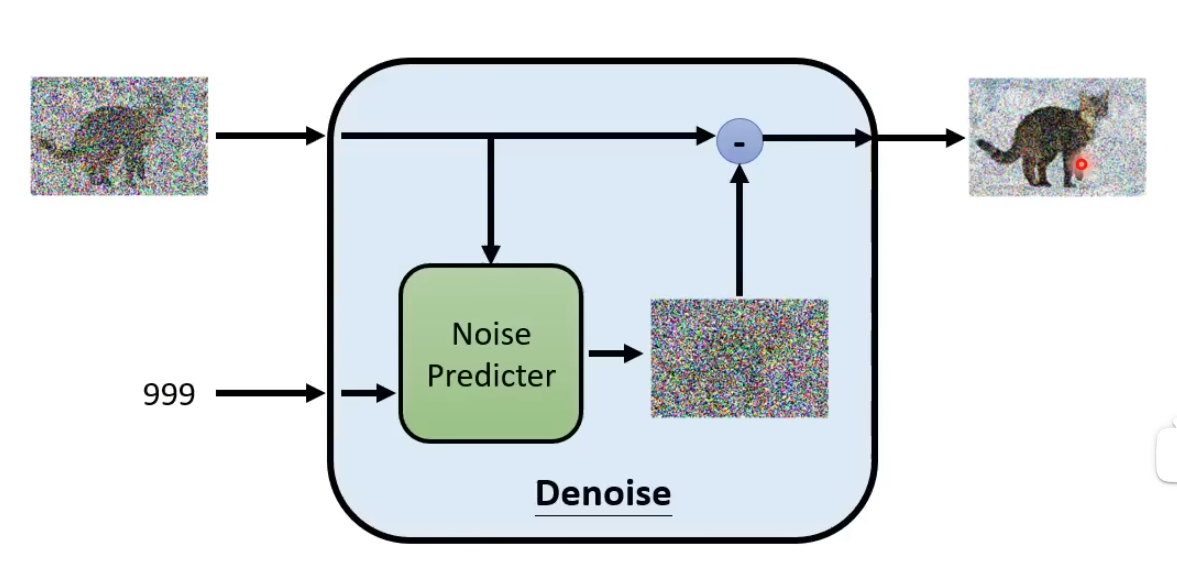
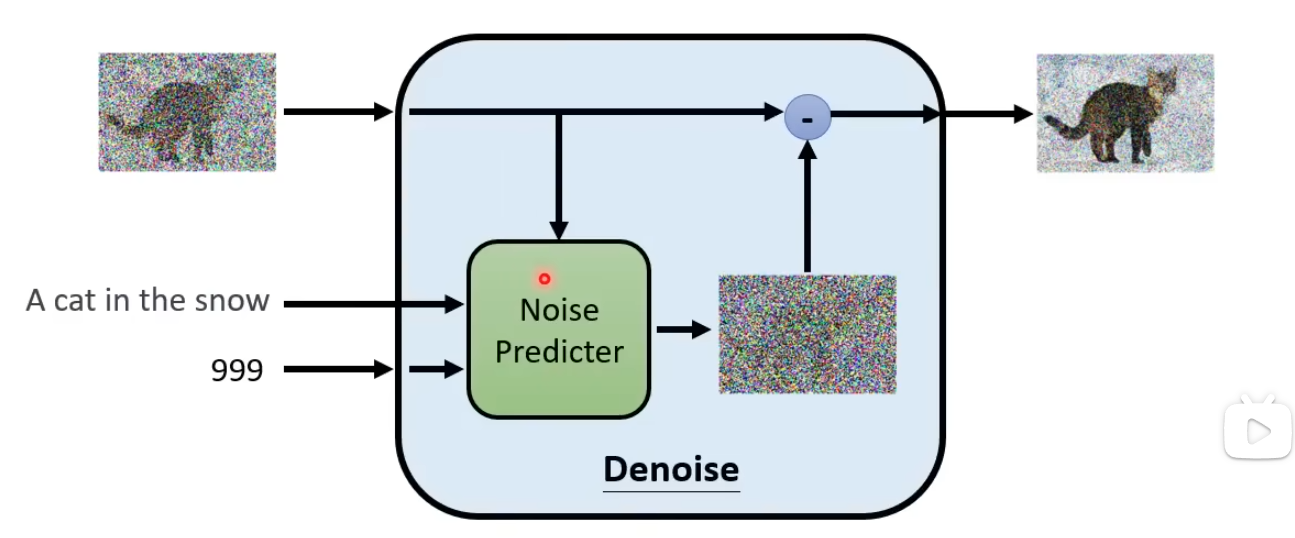
Denoise
- 输入:带噪声的图片、当前Step(表示当前Noise严重程度)
- 输出:去噪后的图片
- Noise Predictor: 预测图片中的噪声是什么
Denoise传入带噪声图片和Step,通过估计噪声图片,结合原始图片去噪,生成去噪后的图片。
如果能生成一张带Noise的猫,那和画一只猫又有什么区别呢。但是估计Noise比直接生成猫要简单。
Forward Process
我们可以在数据集中找一只猫,然后不断添加噪声用于训练Denoise,这叫Forward Process

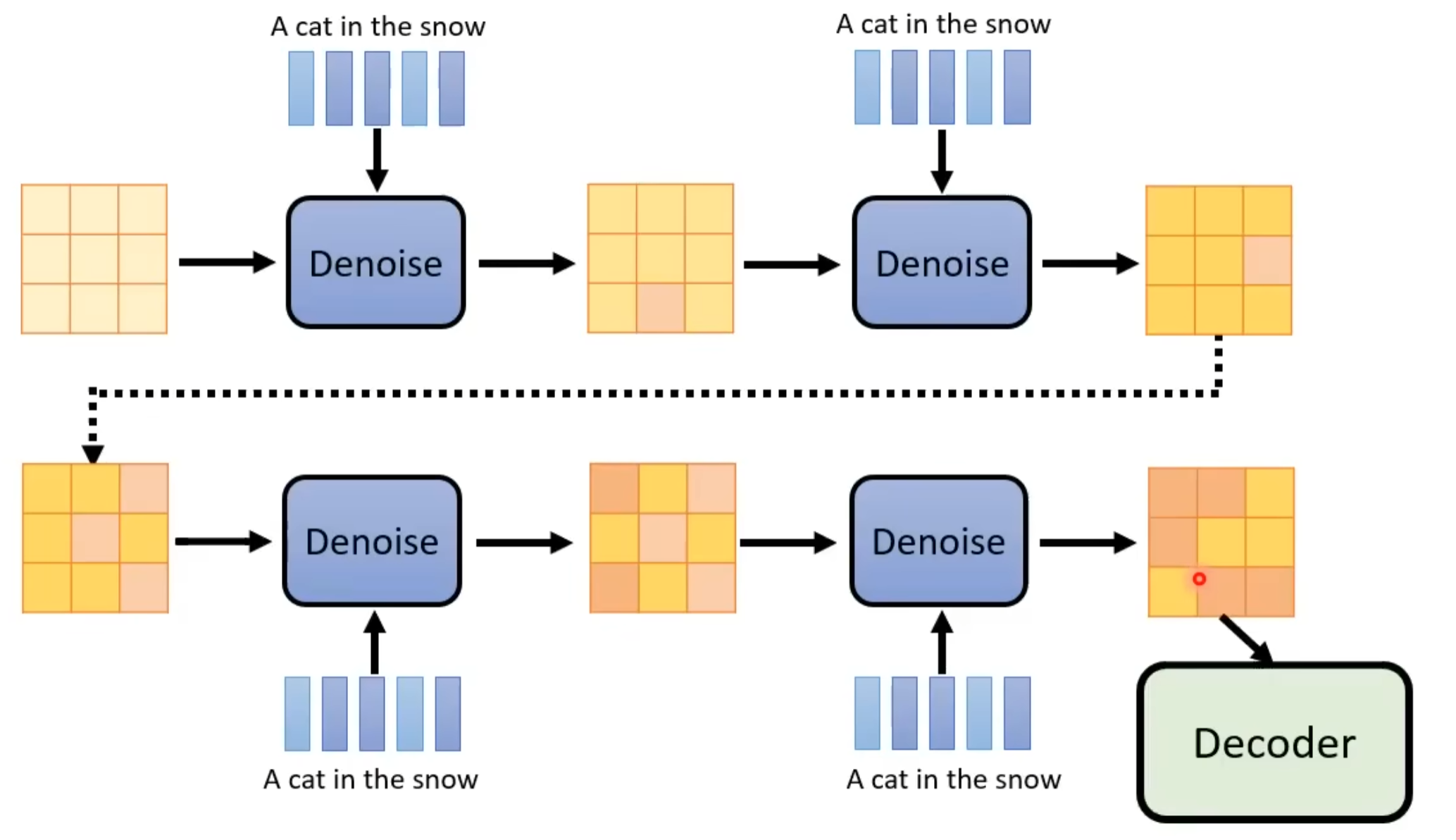
Text-to-Image
要实现文生图,需要大量的图像数据,laion拥有5.85B图片,并带多种语言:LAION-5B: A NEW ERA OF OPEN LARGE-SCALE MULTI-MODAL DATASETS | LAION
将图片描述加入Denoise中,那么就可以文生图了。
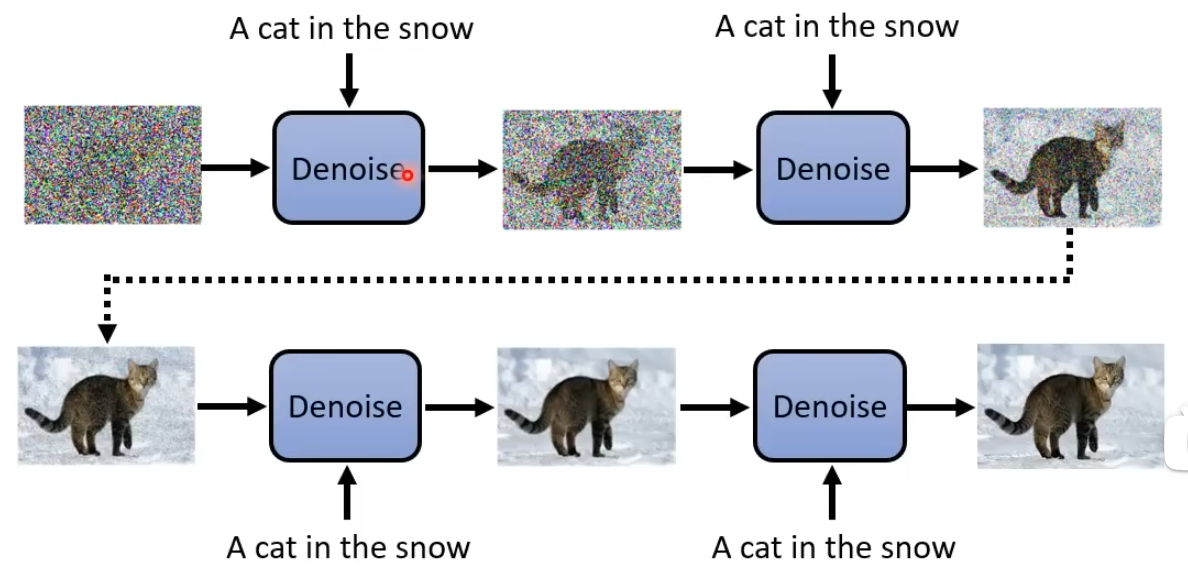
现在Noise Predictor需要增加一个输入:
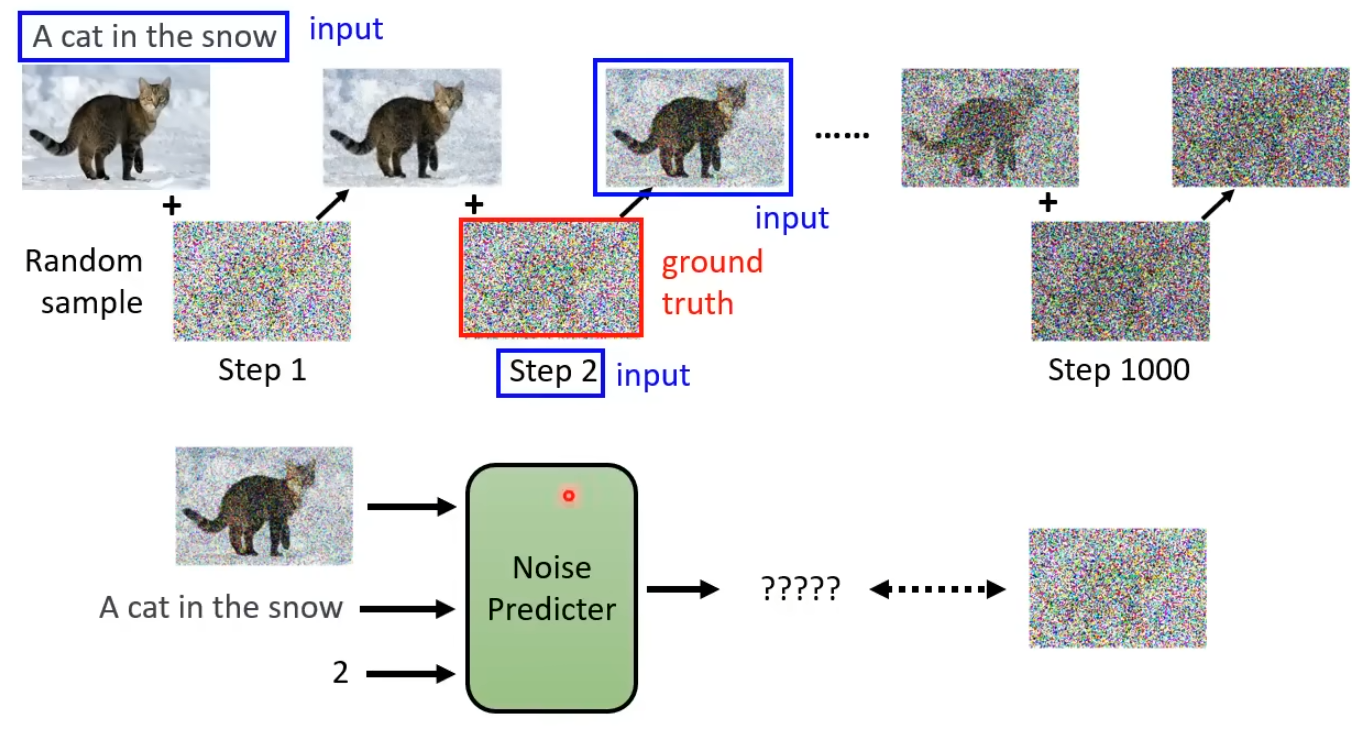
DDPM算法

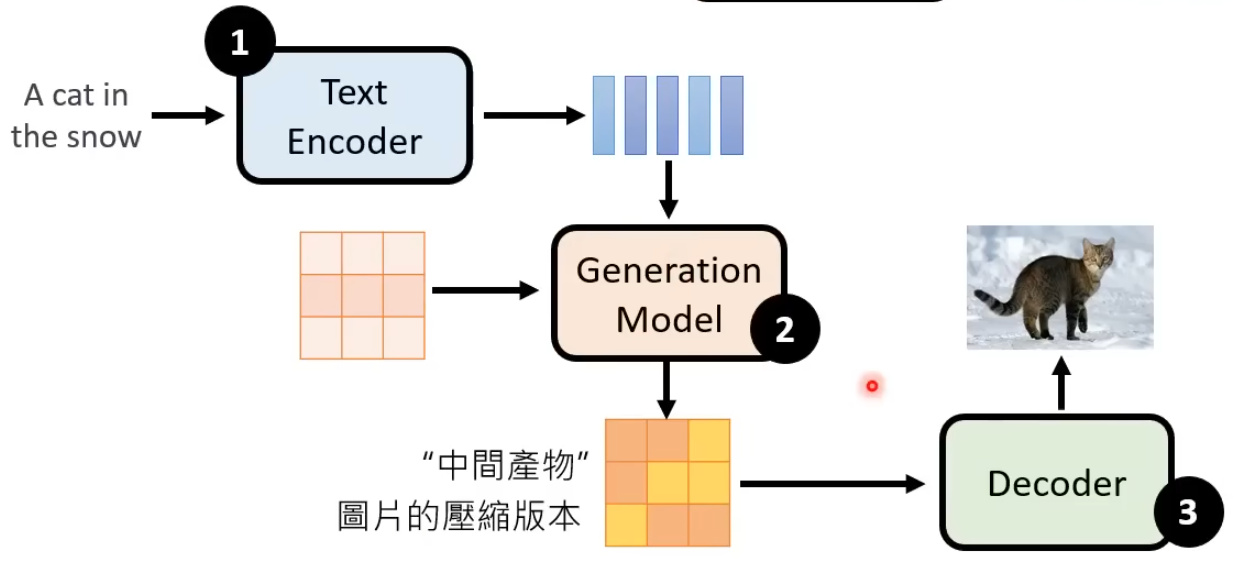
框架
包含三个部分:
- 文字编码器(Text Encoder):将文字编码成易于机器理解的
- 生成模型(Generation Model):结合图片和文字,压缩成一个中间产物
- 解码器(Decoder):将中间产物生成为图片
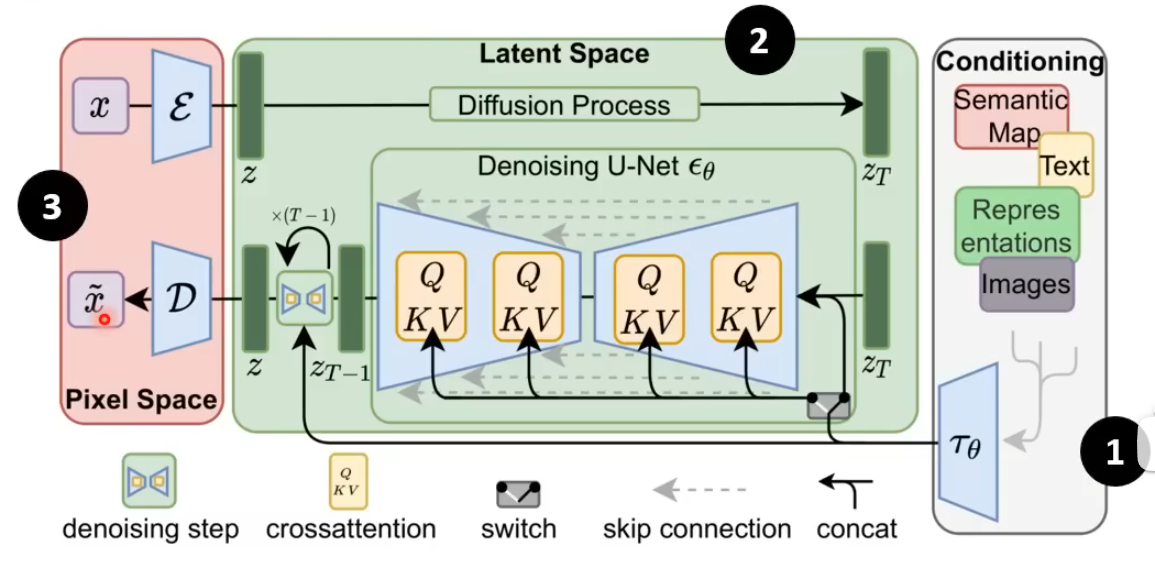
例如Stable Diffusion的:
DALL-E系列的:
 Google的:
Google的:
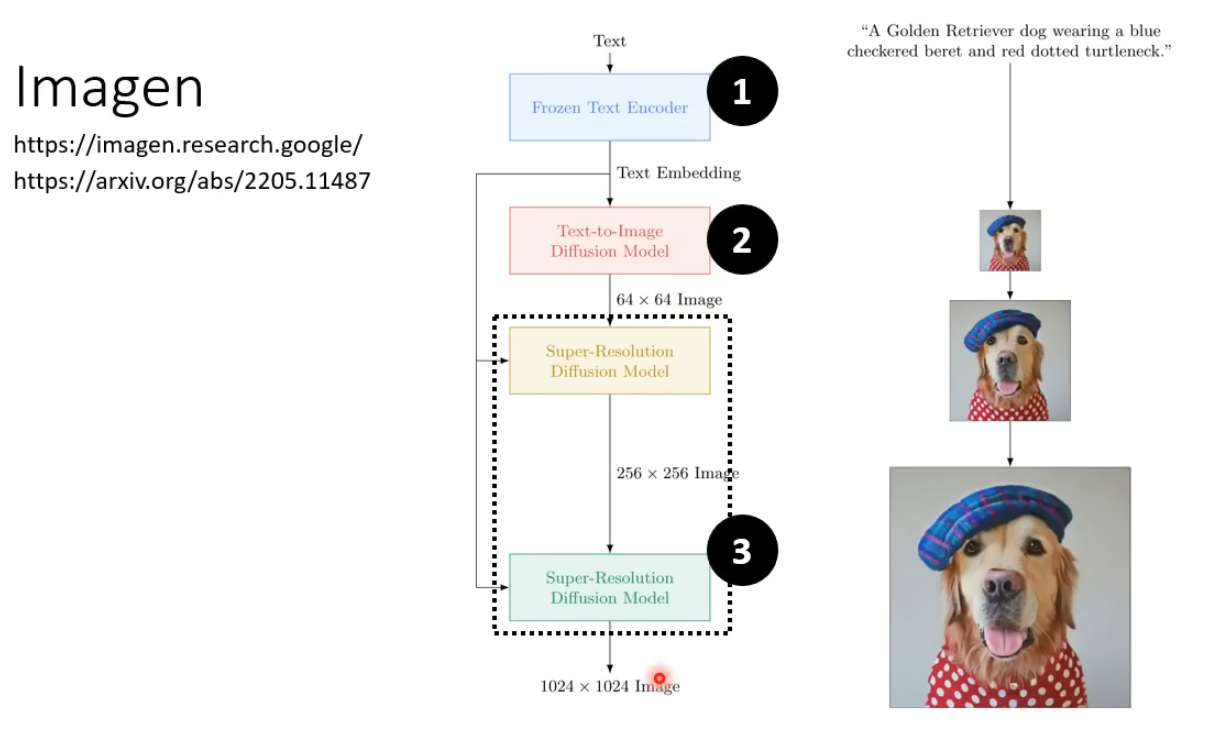
Text Encoder

文字编码器对结果的影响很大,随着Encoder越来越大,生成的结果越来越好。—https://arxiv.org/abs/2205.11487
Decoder
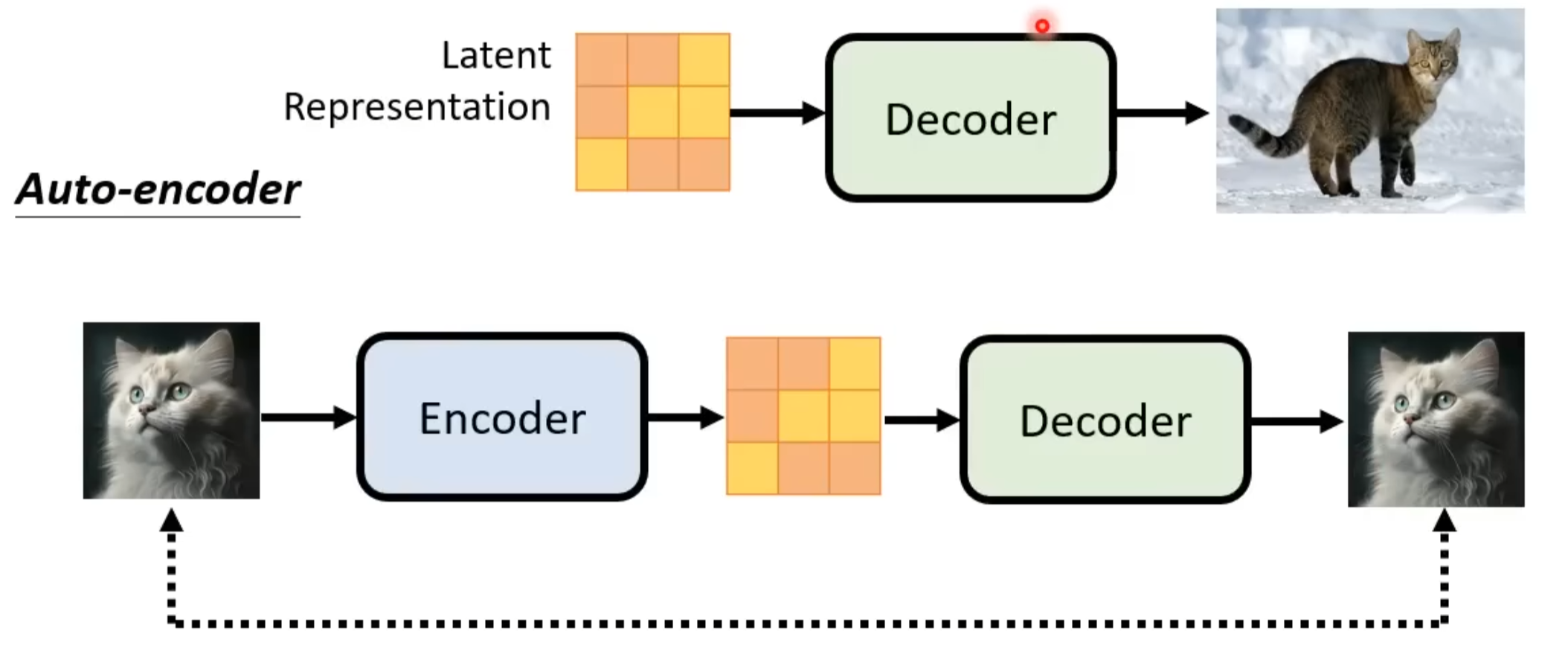
如果中间产物是一个小图,那么Decoder需要将小图变成一个大图。在训练时可以将大图变小图。

如果是中间产物latent representation,那么需要额外的Encoder步骤,但Decoder得到的仍然是小图/原图。
Generation Model
原来的Noise加在图片上,但是现在需要加载Latent Representation上