Contrastive Language-Image Pre-Training (CLIP) 是一种用于学习图像和文本之间关联的深度学习方法。它由OpenAI在2021年提出,旨在学习一个通用的、可迁移的视觉-语言表征。一共使用400M对图像-文本对训练,代码可在github找到。
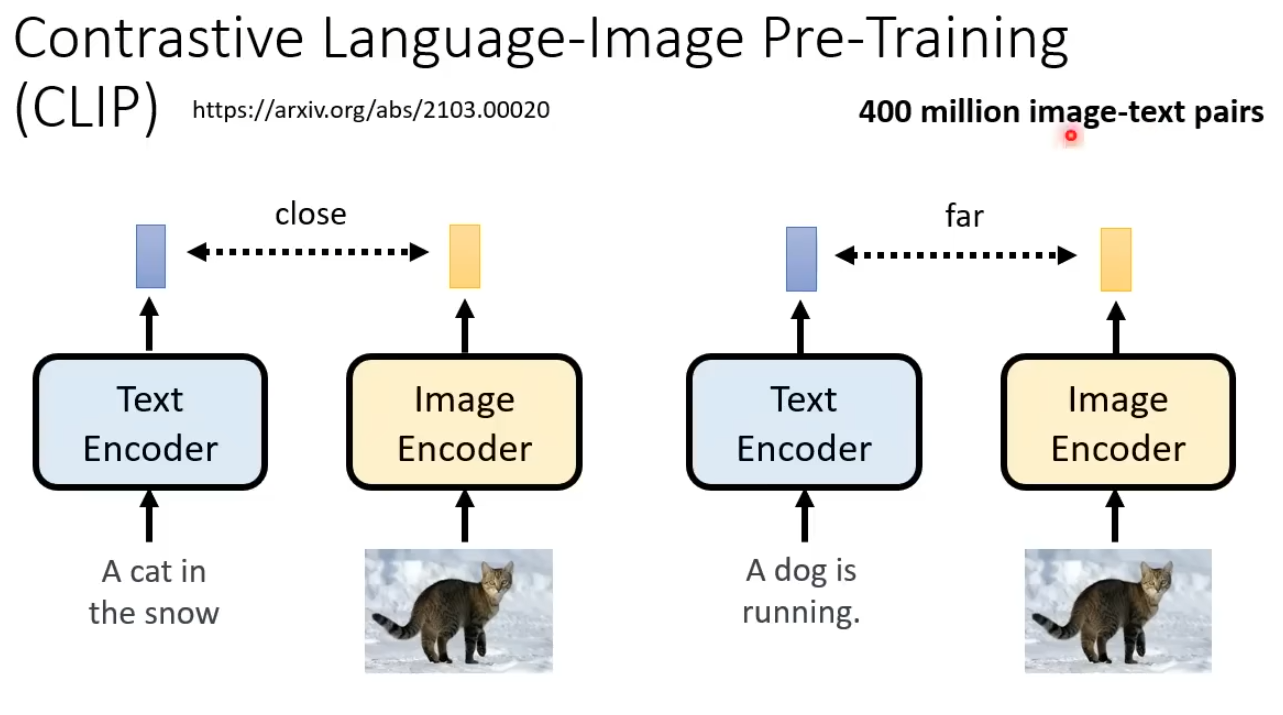
CLIP的主要思想是通过对比学习,使得图像编码器和文本编码器学习到对齐的特征表示。具体来说:
-
使用一个图像编码器(如Vision Transformer)将图像映射到特征空间,得到图像表征。
-
使用一个文本编码器(如Transformer)将与图像相关的文本映射到同一特征空间,得到文本表征。
-
最大化匹配的图像-文本对的相似度,同时最小化不匹配对的相似度。这促使图像和文本在特征空间中的表示趋于一致。
-
在大规模图像-文本数据集(如4亿个图像-文本对)上预训练CLIP模型。
预训练后的CLIP模型可以应用于各种下游视觉-语言任务,如图像分类、检索、描述等,展现出很好的零样本和少样本学习能力。 此外,CLIP还表现出一定的鲁棒性和泛化能力。
优势:
- 训练集大,学习到通用的跨模态表征
- 可迁移性强,适用于多种下游任务
- 对抗了数据集偏差,具有一定的鲁棒性