表示潜在特征的总和。
latent representation(潜在表示)是指输入数据的简化模型,例如由神经网络创建的模型。
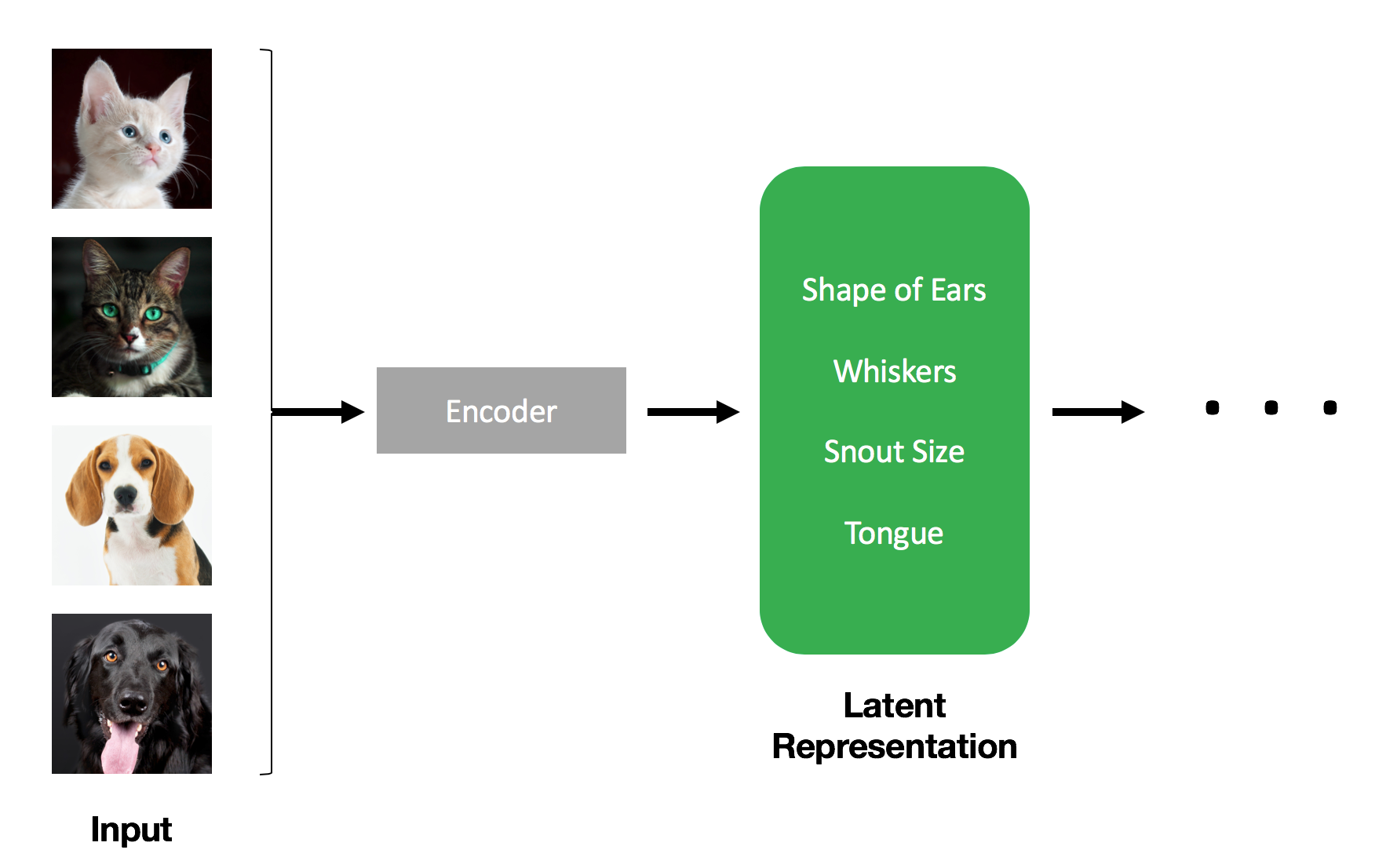
考虑到自编码器(Auto Encoder),该网络的中心层(训练后)将包含输入的数据简化表示(即关键特征的摘要),可用于重建输出。
性质和应用:
-
降维:将高维数据映射到低维空间,同时保留数据的重要信息。这有助于降低计算复杂度,缓解维度诅咒。
-
特征提取:学习到数据的高层语义特征,揭示数据内在的结构和模式。这使得后续的任务如分类、聚类更加容易。
-
生成建模:通过对latent space进行采样和解码,可以生成新的、逼真的数据样本。这是VAE、GAN等生成模型的核心思想。
-
迁移学习:学习到通用的、可迁移的特征表示,使得模型可以更好地适应新的任务和领域。
-
可解释性:latent representation通常具有一定的可解释性,每个维度可能对应着某种语义属性。这有助于理解模型的决策过程。
常见的学习latent representation的方法:
- 自编码器(Autoencoder):通过编码器-解码器结构重构数据
- 变分自编码器(VAE):引入了概率图模型,学习生成模型的latent distribution
- 对比学习(Contrastive Learning):通过最大化正样本对的相似度,学习到判别性的特征表示