分布式理论—现代架构的基石
课件:飞书 - 登录
[TOC]
概述
什么是分布式
分布式系统是计算机程序的集合,这些程序利用跨多个独立计算节点的计算资源来实现共同的目标。可以分为分布式计算、分布式存储、分布式数据库等。
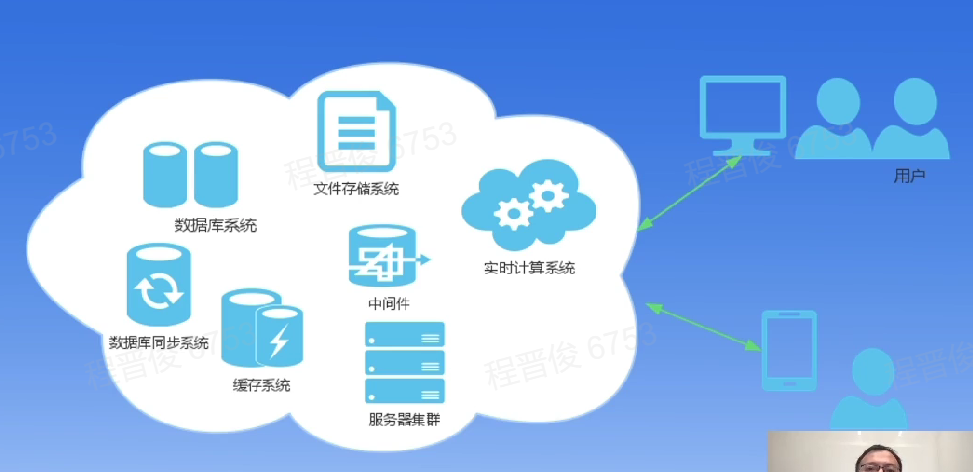
例子:
一台70W的服务器拥有16核心,但是可以买20台一核的机器也可以满足同样的算力要求。但是问题是程序不能在20台机器上跑。
Google为了降低机器成本,不断地找到了分布式计算的方法。
优势与挑战
优点:
- 去中心化:将程序运行在集群里面
- 低成本:刚刚买机器的例子
- 弹性:服务于用户,有波峰有博古,可以在白天服务,夜晚离线计算,促销时扩容,结束后缩容
- 资源共享:一个服务器存储有限,可以搞成一个存储池
- 可靠性高:一个节点硬盘坏了别的节点也可以服务
挑战:
- 普遍的节点故障,故障率按节点数量成指数
- 不可靠的网络:几乎无解,三种状态:对、错、未应答
- 异构的机器与硬件环境:要保证程序在不同环境都能运行,性能也不可预测
- 安全:集中式系统被攻破破坏有限,集群被破环影响深远
Why-How-What
使用者视角:
- Why
- 数据爆炸,对存储和计算有大规模的需求
- 降低成本
- How
- 了解:分布式框架
- 了解:分布式系统
- What
- 清理故障,负载,一致性
- 明确稳定性要求,制定分布式方案
学习者视角:
- Why
- H后端开发必备技能
- 理解后台协作机理
- How
- 了解:分布式理论
- 了解:一致性协议
- What
- 要点深入
- 应用于实践
常见分布式系统
分布式存储
- Google File Storage(GFS):google分布式文件系统
- Ceph:统一分布式存储系统,涵盖文件、块、对象
- Hadoop HDFS:基于GFS的开源分布式文件系统
- Zookeeper:高可用分布式数据管理与系统协调方案
分布式数据库
- Google Spanner:google可扩展、全球分布式数据库
- TiDB;开源分布式关系型数据库(国内)
- HBase:开源NoSQL数据库
- MongoDB:文档数据库
分布式计算
- Hadoop:基于MapReduce的分布式计算框架
- Spark:在Hadoop基础上,基于内存存储数据
- YARN:分布式资源调度
系统模型
故障模型
根据故障的处理难度划分,最难处理的是拜占庭故障
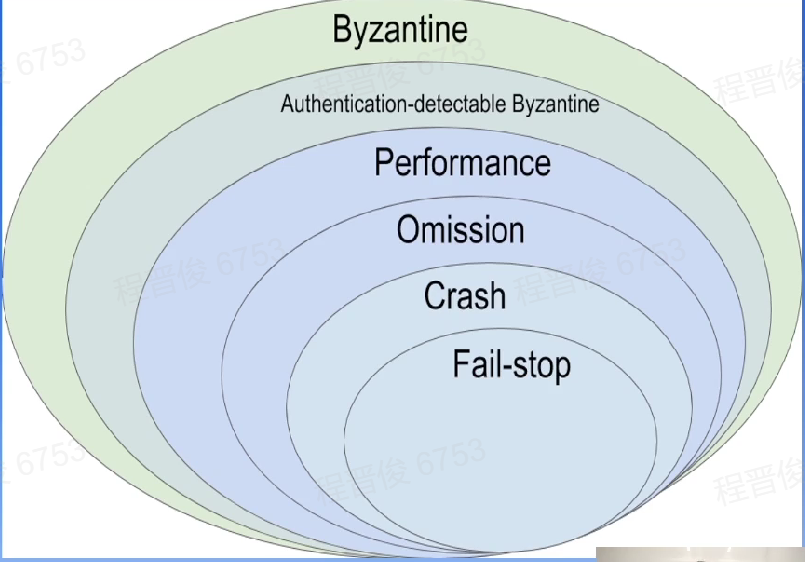


拜占庭将军问题
引入:两将军问题(Two Generals’Problem):两支军队的将军只能派信使穿越敌方领 将互相通信,以此约定进攻时间。该问题希望求解如何在两名将军派出的任何信使都可能被俘虏的情况下,就进攻时间达成共识。
结论是,两将军问题是被证实无解的电脑通信问题,两支军队理论上永远无法达成共识。
-
方案一:同时发送N个信使,任何一个达到对方军队,都算成功。
-
方案二:设置超时时间,发送后未在一定时间返回,则加派信使。
共识与消息传递的不同:即使保证了消息传递成功,也不能保证达成共识 TCP三次握手是在两个方向确认包的序列号,增加了超时重试,是两将军问题的一个工 程解。
所有系统都不会试图解决拜占庭故障,除了比特币。
思考:
- 与TCP不同
- TCP是为了传输消息
- 两将军是为了建立共识
- 为何三次握手?而不是两次和四次?
- 一次确定自己的消息未被截获
- 一次确定对方的消息未被截获
- 一共需要传递三次
- 挥手过程中,如果FIN报文丢失,发生什么?

三个将军的情况
更加普适的场景,例如3个将军ABC互相传递消息,消息可能丢失也可能被篡改,当有一个将军是叛徒时,整个系统就无法达成一致。

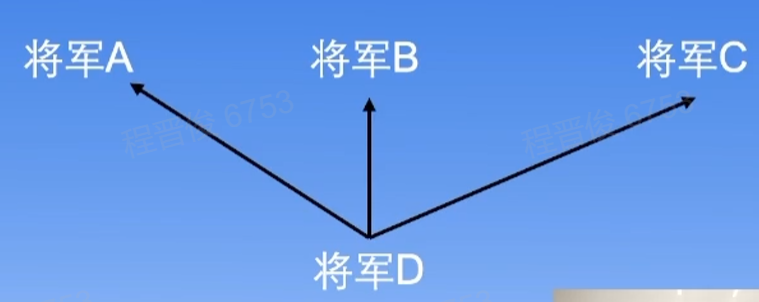
四个将军的情况
4个将军,其中有一个叛徒的情况。
将军D约定将消息作为消息分发中枢,约定如果没有收到消息就撤退。
- D是叛徒:ABC无论收到什么都能达成一致
- D不是叛徒:ABC中有两人将消息正确传输
推论:
在 个将军中有 个叛徒的情况下经过 轮协商,一定能达成一致
共识和一致性
AB为读端,C为写端
最终一致性
C在写是AB会读到0或者1。
当C写入完成后,AB能读到一致的数据

线性一致性
A读到 x=1 后及时更新消息,将消息同步给其他客户端,其他客户端能立即获知 x=1
如果要保证线性一致性,多个节点之间需要协商,损伤了系统的可用性

系统模型—时间和事件顺序
2013年图灵奖作者:time-clocks.pdf (lamport.azurewebsites.net)
happened before
定义:happened before关系,记作
如果a发生在b之前,那么记作
推论:
- , ,可知
当且仅当 ,那么ab事件是并发的
如下图:可推出

逻辑时钟
对每一个节点 定义一个时钟函数 ,它为任意的事件a赋编号
- 如果a,b是相同节点 上的两个事件,a在b之前发生,那么有:
- 如果事件a表示节点 上发送的某条消息,b表示节点 会接受这个消息,有:
- 同一节点的两个连续事件之间肯定有上面图中的”tick line“
利用逻辑时钟,可以对整个系统的事件排序
逻辑时间与物理时间
兰伯特认为时间不是连续的,是离散的(量子)
问题:
当一个节点事件特别多,但是我们认为一个原子时间里面只有一个事件发生。
那么存在一个事件物理时间始终靠后,一个物理时间靠前,但是逻辑时间正好相反。(什么相对论)
理论基础
分布式事务
分布式事务比较难处理,很多系统都在试图避免分布式事务。
两阶段提交
两阶段提交(Two-phase Commit):为了使得基于分布式事务架构下所有节点在进行事务提交时保持一致性而设计的一直演算法
三个假设:
- 协调者(Coordinator)与参与者(Participants)互相进行网络通信
- 所有节点采用预写式日志,日志写入后就被保存到可靠的存储设备上
- 所有节点不会永久损害,即损坏后还可以恢复
情况
- 正常情况:
- prepare阶段:coordinator给participants发:准备减去1W块钱,participants回复收到
- commit阶段:coordinator给participants发:快提交,participants回复完成

- 异常场景:
- coordinate不宕机,participants宕机:
- 触发回滚操作

- coordinate宕机,participants不宕机:
- 另立协调者,待查询状态后再次尝试提交
- 都宕机了:
- 无法确认状态,数据库管理员介入
- coordinate不宕机,participants宕机:
问题
性能:需要多次网络通信,耗时过大,资源需要锁定,徒增资源等待时间
网络分区带来的数据库不一致:一部分参与者收到了commit,但另一部分没有。回滚日志,重做事务。
IOE:IBM的服务器,Oracle的数据库,emc的存储
思考:
-
如何保证日志被保存在可靠设备上
- 采用分布式存储
-
prepare后没收到ack怎么办?
三阶段提交
将prepare阶段拆分成:cancommit 和 precommit阶段
-
解决了单点故障问题和阻塞问题
-
引入超时机制,等待超时后继续事务的提交
-
性能问题
-
网络分区的数据一致性问题

MVCC
锁
- 悲观锁:整个操作都上锁,性能差
- 乐观锁:只在更新时上锁,遇到冲突时麻烦

MVCC是一种并发控制的方法,维持一个数据的多个版本使读写操作没有冲突。所以既不会阻塞写,也不阻塞读。MVCC 为每个修改保存一个版本,和事务的时间戳相关联。可以提高并发性能,解决脏读的问题。
Spanneri论文里通过一个卫星,使用TrueTime API提供一个物理时钟的方式。服务器时钟偏差在1到7ms之间。
- S1提交事务时间:s1=max(15,7+7)=15ms
- S2提交事务时间:s2=max(13,12+7)=19ms

另外一种时间戳的实现:时间戳预言机(TSO),采用中心化的授时方式,所有协调者向中心化节点获取时钟。优点是算法简单,实现方便,但需要每个节点都与他进行交互,会产生一些网络通信的成本。TSO的授时中就需要考虑低延迟,高性能以及更好的容错性。
共识协议
Quorum NWR模型
基于三个要素:
- N:在分布式存储中有多少分备份数据
- W:一次成功的更新操作至少有W份成功写入
- R:一次成功的读取操作至少有R份成功读取
NWR模型将CAP的选择交给用户
为了保证强制一致性:必要不充分条件,读取 数据可能是老的。

问题:
读者如果读到副本1和副本2,得出v=3的结论,如果读到副本2和副本3,得出v=2的结论 问题根源:允许数据被覆盖

RAFT协议
Rft协议是一种分布式一致性算法(共识算法),即使出现部分节点故障,网络延时等情况,也不影响各节点,进而提高系统的整体可用性。Raft是使用较为广泛的分布式协议。一定意义上讲,RAFT也使用了Quorum机制。
- Leader-领导者,通常一个系统中是一主(Leader)多从(Follower).Leader负责处理所有的客户端请求,并向Followerf同步请求日志,当日志同步到大多数节点上后,通知Follower提交日志。
- Follower-跟随者,不会发送任何请求。接受并持久化Leaderl同步的日志,在Leader告知日志可以提交后,提交日志。当Leader出现故障时,主动推荐自己为Candidate.
- Candidate-备选者,Leaderi选举过程中的临时角色。向其他节点发送请求投票信息。如果获得大多数选票,则晋升为Leader。。

- Log(日志):节点之间同步的信息,以只追加写的方式进行同步,解决了数据被覆盖的问题
- Term(任期号):单调递增,每个Term内最多只有一个Leader
- Committed:日志被复制到多数派节点,即可认为已经被提交
- Applied:日志被应用到本地状态机:执行了Iog中命令,修改了内存状态

Paxos协议
分布式实践
MapReduce
分布式KV
资料
课件:分布式理论 - 现代架构基石.pptx - 飞书云文档 (feishu.cn)
其他
reft协议巧妙的地方
raft协议是Stanford一个学生和他的老师写出来的。