[TOC]
经典案例
数据的产生
下载APP,注册账号:
用户名:jjc
密码:123456
按下注册按钮,此时数据产生,并发送给服务器端

数据持久化过程:
- 校验数据合法性
- 修改内存
- 写入存储介质

潜在问题:
- 数据库怎么保证数据不丢
- 数据库多人修改问题
- 除了数据库,还能使用其他的存储系统吗
- 数据库只能存储结构化数据吗
- 数据库操作方式以及编程语言
存储 & 数据库简介
2.1-系统概览
存储系统就是提高读写、控制类接口,能够把数据安全有效地持久化的软件
相关内容:
用户、设备、内存、磁盘、网络

2.2.2-系统特点
- 性能敏感
- 既简单又复杂
- 硬件敏感

2.2.3-存储器层级结构
存储天梯图,需要一个兼顾容量和读写速度的存储介质。
Persistent Memory:兼顾二者不过比较贵

数据如何写到存储介质上
- 缓存很重要,几乎贯穿整个存储体系
- 拷贝很昂贵,尽量减少(使用指针或引用)
- 硬件设备五花八门,需要有抽象统一的接入层

RAID技术
Q:单机存储系统如何兼顾性价比,可靠性,性能?
A:Reduncant Array of Inexpensive Disks
背景:
- 单块大磁盘价格 远大于 多块小磁盘
- 单块大磁盘性能 远小于 多块小磁盘
- 单块磁盘容错能力有限
RAID0:
- 多块磁盘简单组合
- 数据条带化存储,提高磁盘带宽
- 没有容错
RAID1:
- 一块磁盘对应一块镜像盘容错
- 空间利用率低
- 容错强
RAID0 + RAID1:
- 空间利用率50%
- 条带化存储,提高磁盘带宽
2.2-数据库
数据库和存储系统不同
关系型数据库:支持复杂查询语言,支持事务、结构化数据友好
非关系型一般不严格要求结构化,一般职责比较单一
用数据库存储比较简单,但之间文件操作需要直接对byte操作。

关系型数据库支持事务

数据库查询比较简单

主流产品剖析
3.1-单机存储
本地文件系统
Unix哲学:一切皆文件
文件系统管理单元:文件
文件系统接口:遵循VFS统一抽象接口。如Ext2/3/4,sysfs,footfs
Linux文件系统两大数据结构:Index Node,Directory Entry
Index Node;记录文件元数据,如ID、大小、权限、磁盘位置。是文件的唯一标识,总数在格式化时就以确定
Directory Entry:记录文件名,inode指针,层级关系。与inode为 N:1 关系
key-value存储
一切皆kv,key为身份证,value为内容
常见使用方式:put(k, v), get(k)
常见数据结构:LSM-Tree,牺牲读性能追求写性能

3.2-分布式存储
在单机上实现了分布式协议,涉及大量网络交互
分布式文件系统
HDFS:大数据时代的基石(2010年Google)
时代背景:专用高级硬件很贵,Google业务量很大,要求超高吞吐
HDFS核心特点:
- 支持海量数据存储
- 高容错
- 弱化POSIX语义
- 能跑在普通机器上
架构图:

分布式对象存储
Ceph:开源分布式存储系统万金油
核心特点:
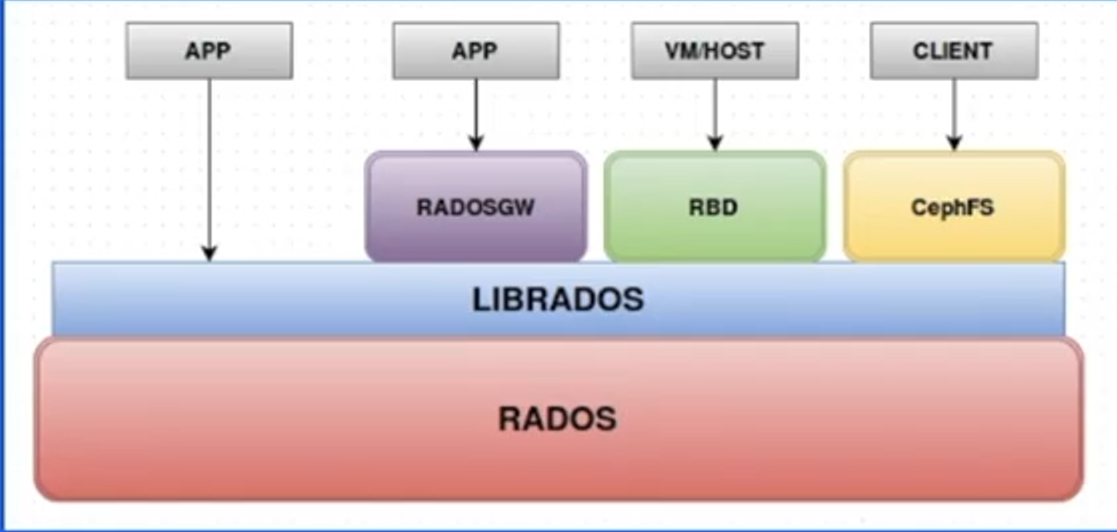
3.3-单机关系型数据库
单机数据库:单个计算机节点上的数据库系统,事务在单机执行,也可能通过网络交互实现分布式事务

如何写入数据

3.4-单机非关系型数据库
DB Engines 排行

Elastic Search天然支持模糊搜索

3.5-分布式数据库
原来问题:容量、性能、网络
存储节点池化,动态缩扩容

弹性问题:

性价比问题:

新技术演进
4.1-架构
Bypass OS Kernel:通过绕过内核,提升存储栈性能瓶颈
SPDK:

- 完全避开OS kernel space,避免内核转换的性能损耗
- 不再使用中断,使用轮询避免很多次中断
- 无锁,降低并发开销(Lock-Free Queue)
4.2-硬件
- 存储介质变更
- 计算单元变更
- 网络硬件变更
RDMA网络
- 传统网络栈处于内核态,存在内核转换
- RDMA网络属于kernel bypass,不经过传统网络协议栈,将用户态虚拟内存映射给网卡,减少拷贝和CPU开销
Presistent Memory
- IO时延再SSD和Memory之间,百纳秒
- 可用作内存、可用作磁盘
可编程交换机
P4 Switch,配有编译器、计算单元、DRAM
可在交换机层对网络包做计算逻辑。数据库领域可做缓存一致性协议
CPU/GPU/DPU
- CPU:multi-core 转向 many-core
- GPU:算力、显存提升
- DPU:异构计算,减小CPU的workload
4.3-理论
4.4-AI + DB
智能存储格式转换:行存、列存混合
