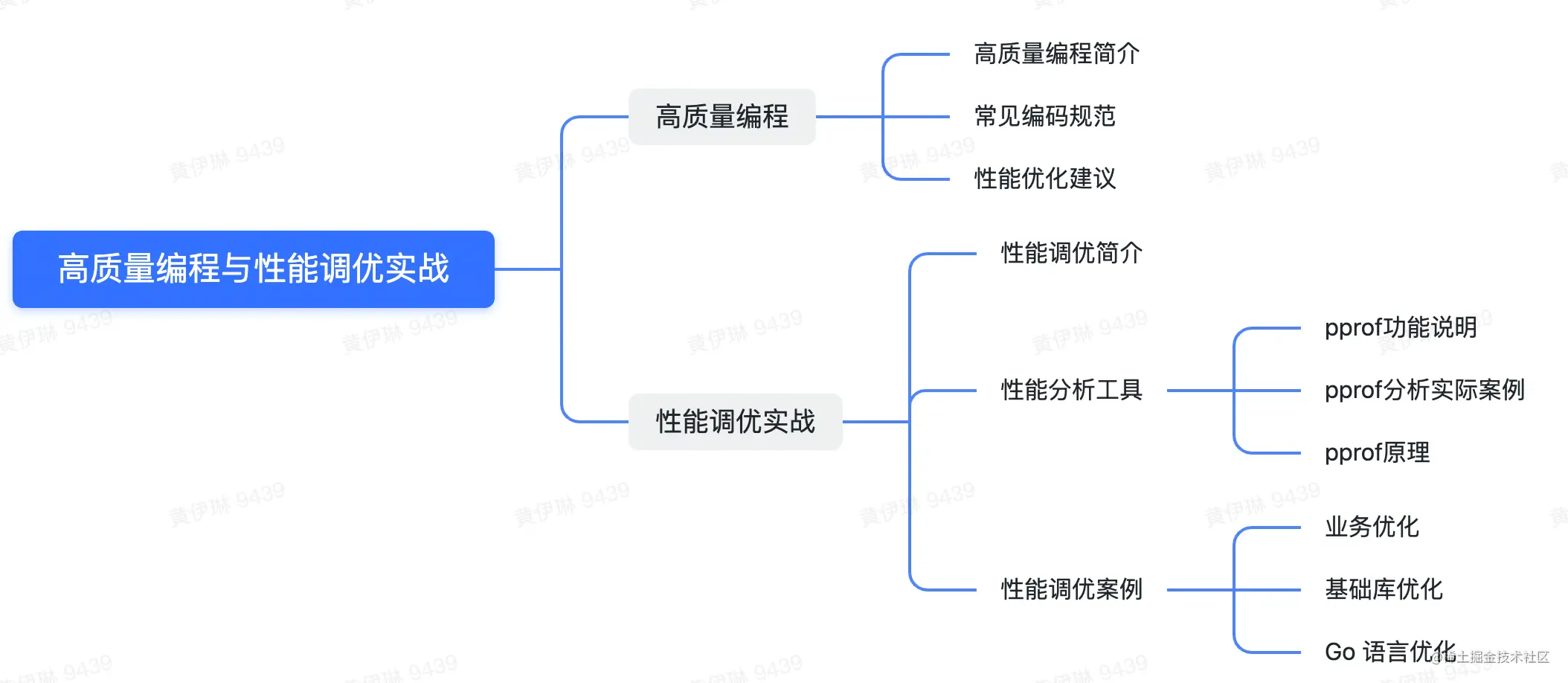
1 - 高质量编程
1.1 简介
高质量代码:准确可靠,简洁清晰
编程原则:
- 简单性:以简单清晰的逻辑编写代码
- 可读性:代码是给人看的
- 生产力:团队效率最重要
1.2 - 编码规范
格式:gofmt自动格式
注释:好的代码有很多注释,坏的代码需要很多注释
命名:简洁、公共方法要大写、离使用的地方越远需要携带更多的上下文

// 越简洁越好
for index:=0; index<len(s); index++{} // bad
for i:=0; i < len(s); i++{} // good
// 上下文
func (c*Client) send(req*Request, deadline time.Time) // good
func (c*Client) send(req*Request, t time.Time) // good好的命名就像个好笑话。如果你必须解释她,那就不好笑了。 ——Dave Cheney
编码规范:避免嵌套if、减少代码缩进
异常处理:
- 简单错误:
errors.New,反正只出现一次 - wrap:使得一个error嵌套另外的wrror,便于将错误包含在错误链中
- 错误判定:
errors.ls,可以判断错误链上是否存在特定错误 - 获取错误链上特定错误:
errors.As - panic:无法被程序解决的错误,不建议,一般用于init或者main
- 错误恢复:
recover,只能在defer函数中使用,嵌套无法生效,只在当前goroutine生效
1.3 - 性能优化建议
前提:正确性,越高级的方法越容易出错
目的:性能在时间和空间上的综合评估优化,有时时间效率和空间效率会对立
cd start
go test -bench=. -benchmemoutput:
goos: linux
goarch: amd64
pkg: go-practice/start
cpu: AMD Ryzen 5 3550H with Radeon Vega Mobile Gfx
BenchmarkFib10-8 2494176 505.4 ns/op 0 B/op 0 allocs/op
PASS
ok go-practice/start 1.762sslice优化
slice预分配内存,避免slice重新分配内存
cd benchslice/ && go test -bench=. -benchmemOutput:
goos: linux
goarch: amd64
pkg: go-practice/benchslice
cpu: AMD Ryzen 5 3550H with Radeon Vega Mobile Gfx
BenchmarkNoPreAlloc-8 1087354 1362 ns/op 2040 B/op 8 allocs/op
BenchmarkPreAlloc-8 3178473 382.9 ns/op 896 B/op 1 allocs/op
PASS
ok go-practice/benchslice 5.472sslice大内存未释放:使用copy而不是re-slice指令
在已有基础上创建slice不会创建新的数组,如果在大切片上新增小切片,底层数组会因为存在引用得不到释放。
map预分配内存
向map不断条件元素时会rehash,如果提前知道规模就可以预定义内存
string处理
使用stringbuilder或者bytebuffer处理字符串拼接问题
空结构体
struct{}不占任何空间,且具有很强的扩展性,可作为占位符
可以实现set,因为值使用bool的话会占用1byte空间
atomic包
原子操作,atomic通过硬件实现,而不是OS实现
2 - 性能调优工具
简介
- 依靠数据而不是猜测
- 找准主要矛盾—优先处理瓶颈点
- 不要过早优化
- 不要过度优化
工具
使用 pprof 分析程序CPU占用等问题

pprof功能说明
- 下载示例代码:<https://github.com/wolfogre/go-pprof-practice
- 运行
main.go,打开 http://localhost:6060/debug/pprof/
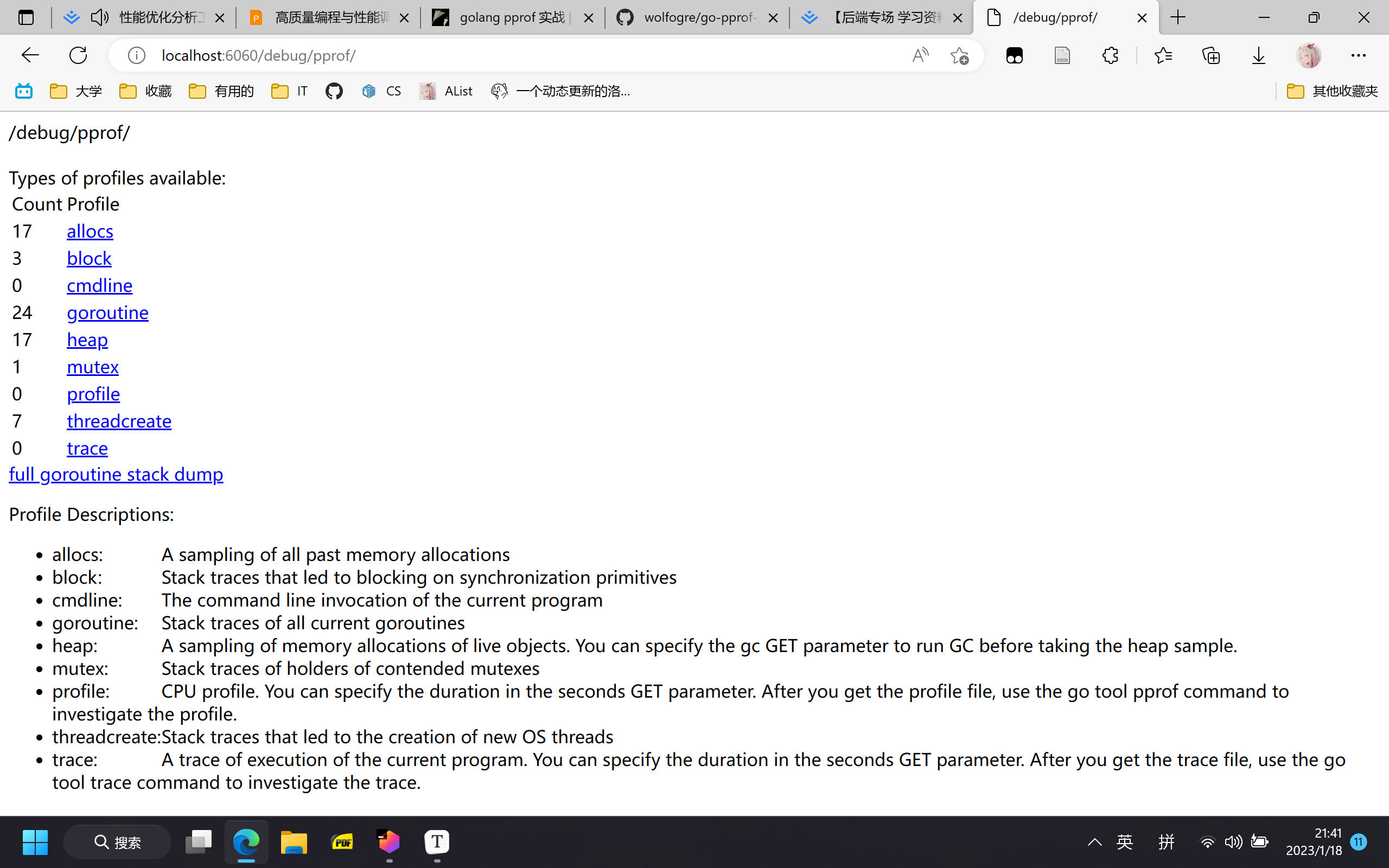
点击相应连接会跳转到对应指标,不过我们有可视化的工具处理
CPU排查
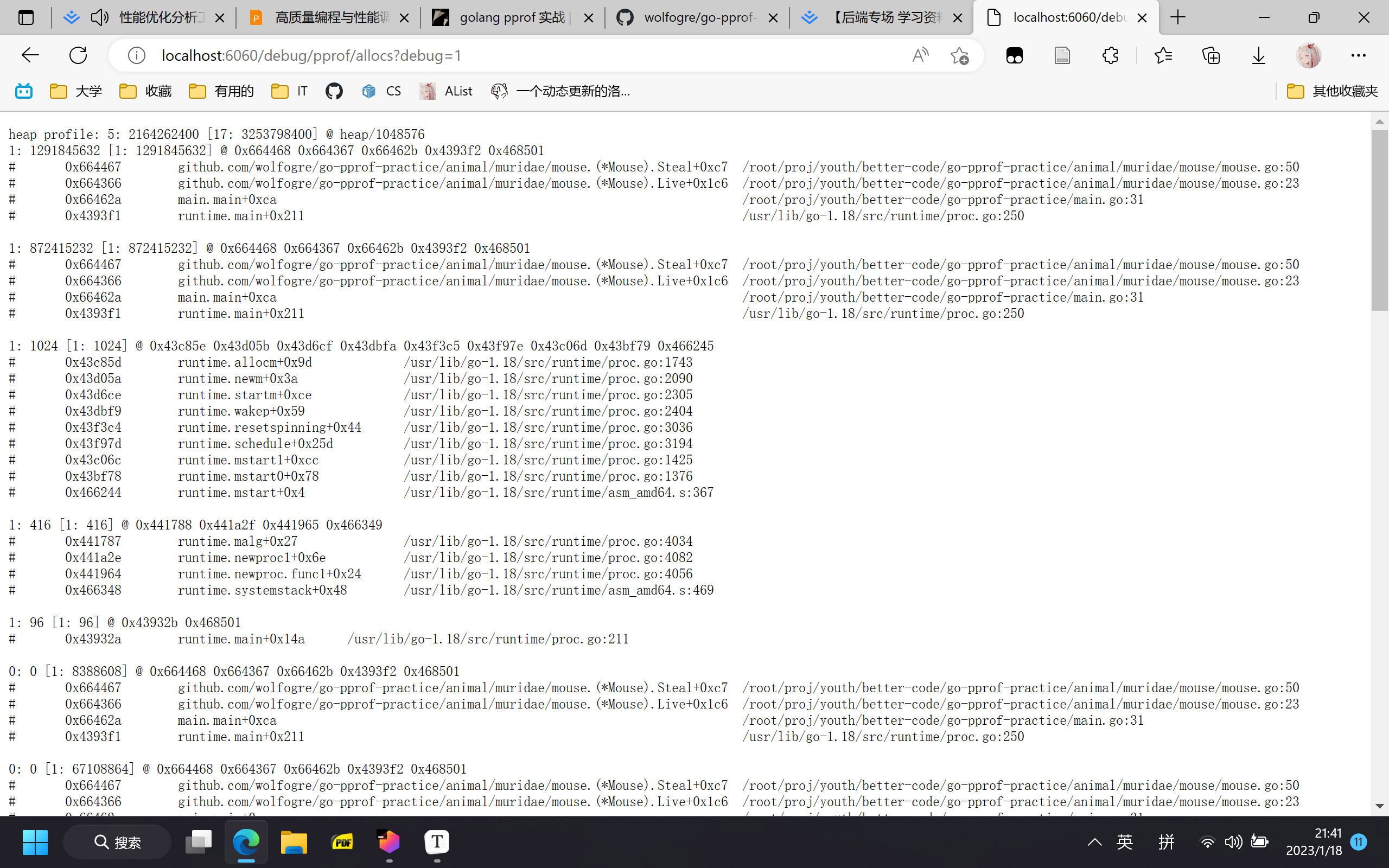
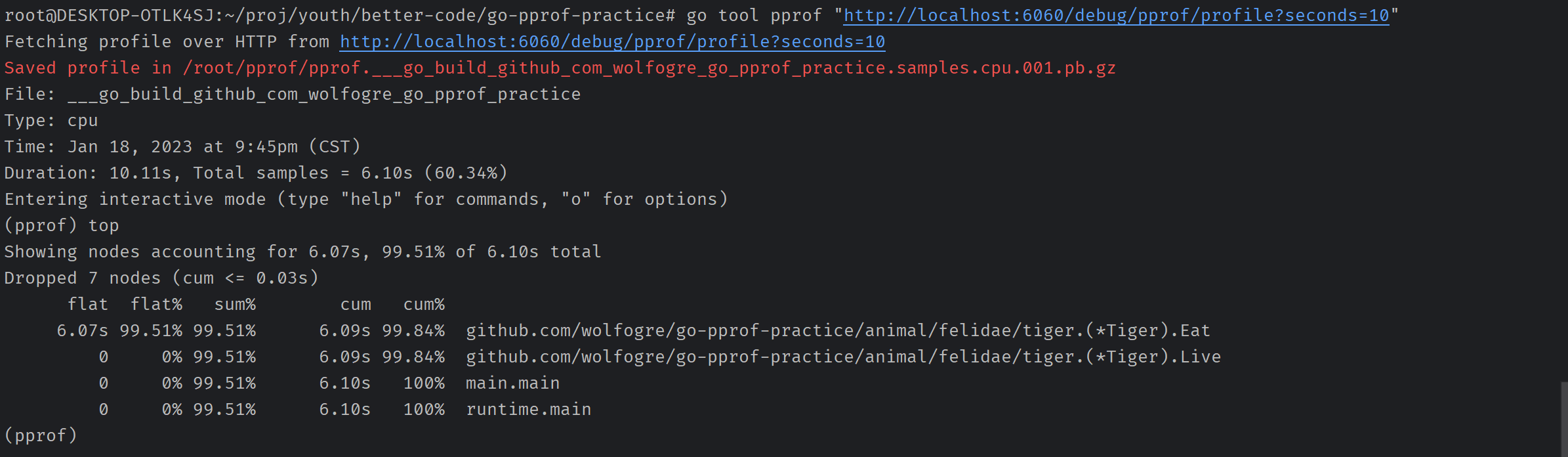
命令行执行:go tool pprof "http://localhost:6060/debug/pprof/profile?seconds=10"
这会让pprof采样10s的CPU数据,通过这些数据我们可以知道问题出现在哪儿
执行top可以查看cpu占用排序,可以观察到 tiger.Eat 占用了最多的CPU,我们可以去里面排查一下
flat == cum:函数没有执行其他函数flat == 0:函数只有其他函数的调用
使用list XXX可以使用正则表达式筛选函数,这里执行list Eat:
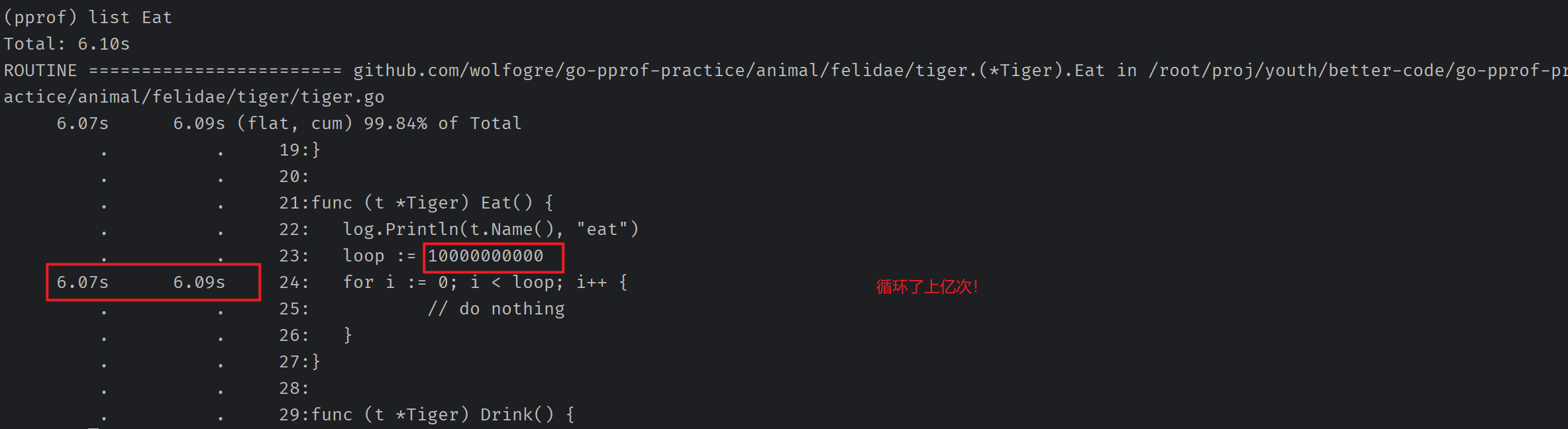
发现执行了空方法上亿次,赶紧把它删掉。
命令行不方便的话可以执行web命令(需要安装graphviz),同样可以发现Eat函数最占CPU

Heap
命令行执行:go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/heap",这时只需要打开浏览器的8080端口就可以可视化地看到heap分析
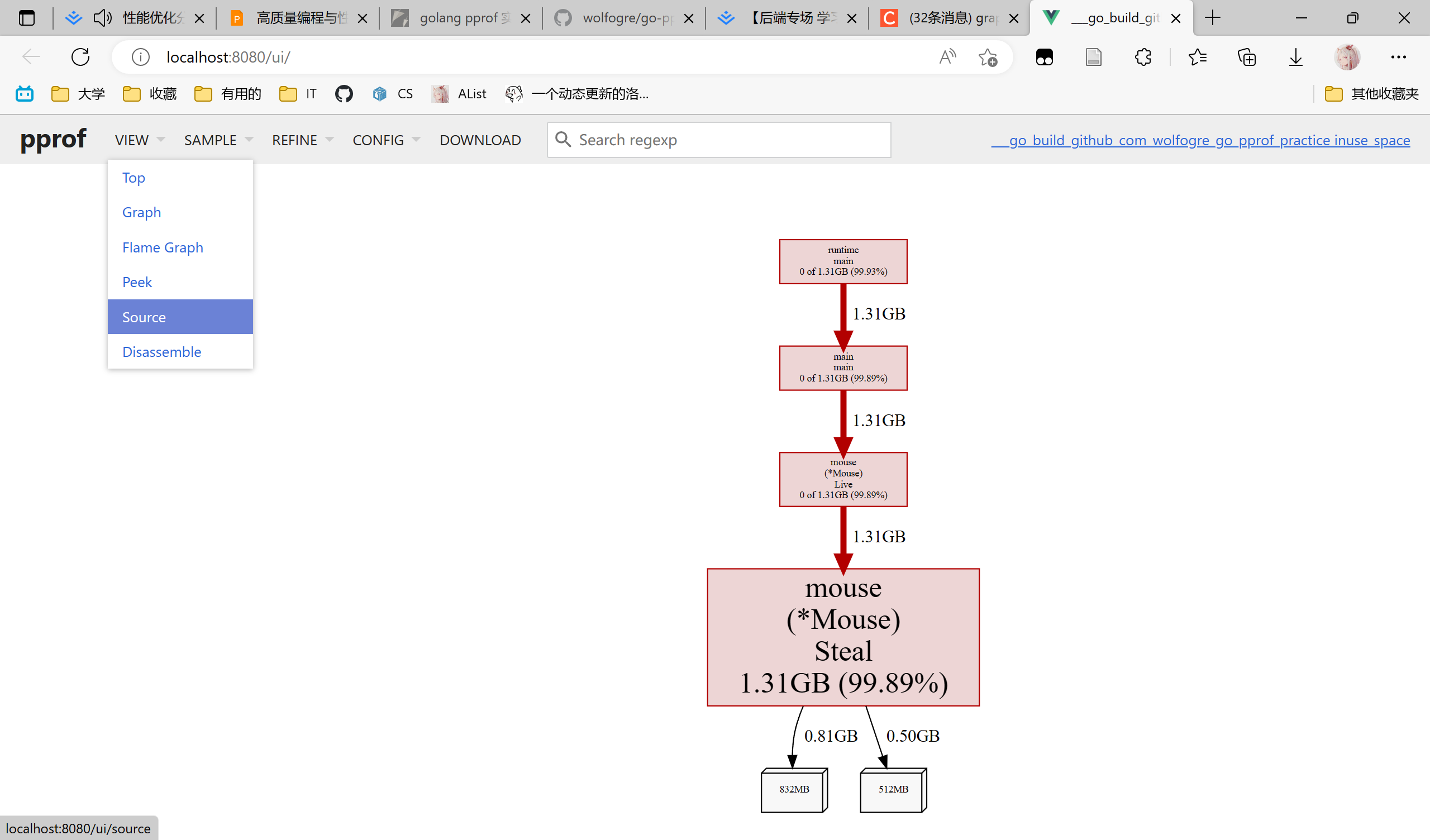
哇,老鼠偷了1G的空间,得赶紧把窟窿补上
goroutine
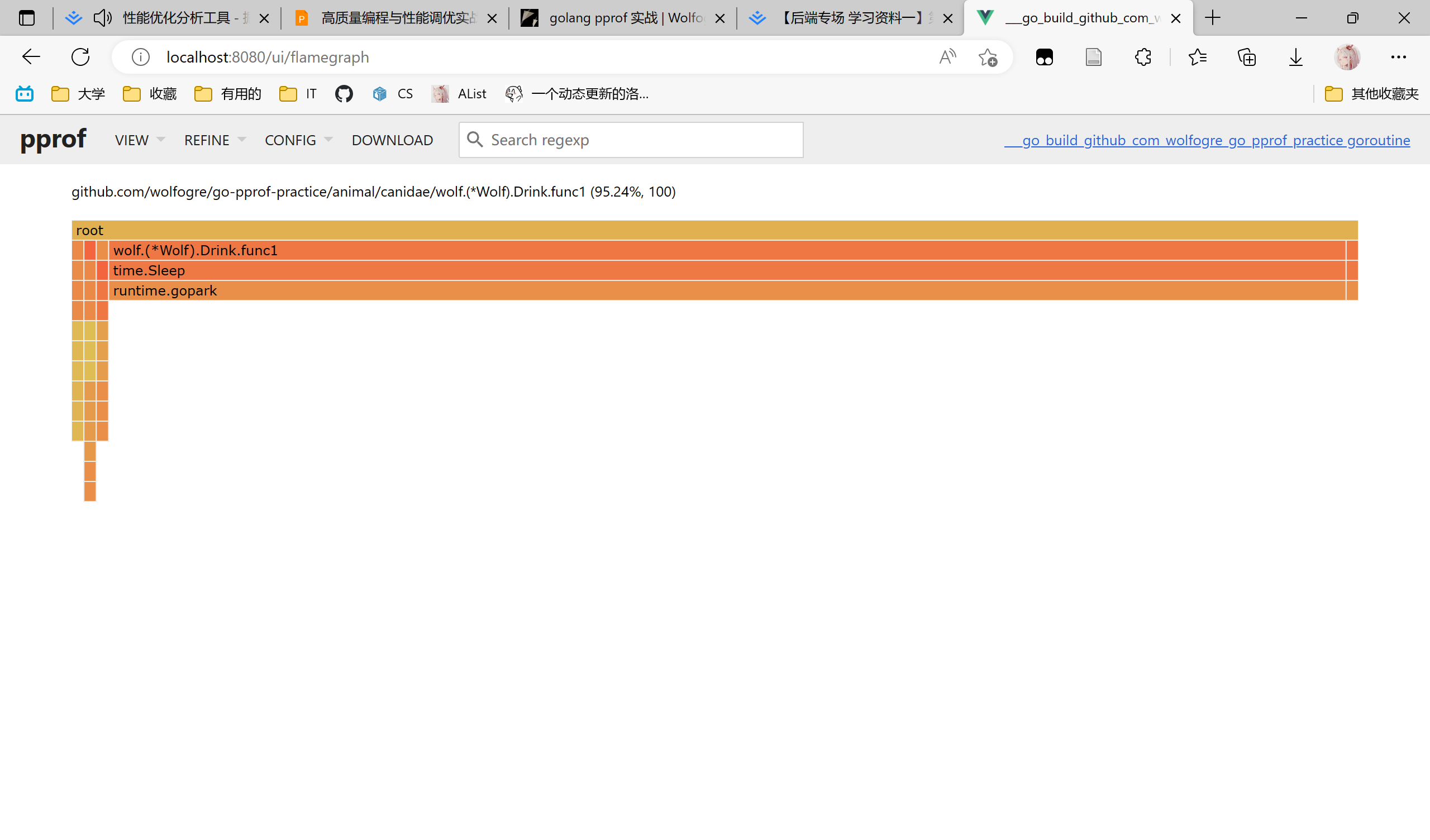
执行:go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/goroutine"
左上角打开火焰图,发现 Wolf.Drink 占用最多
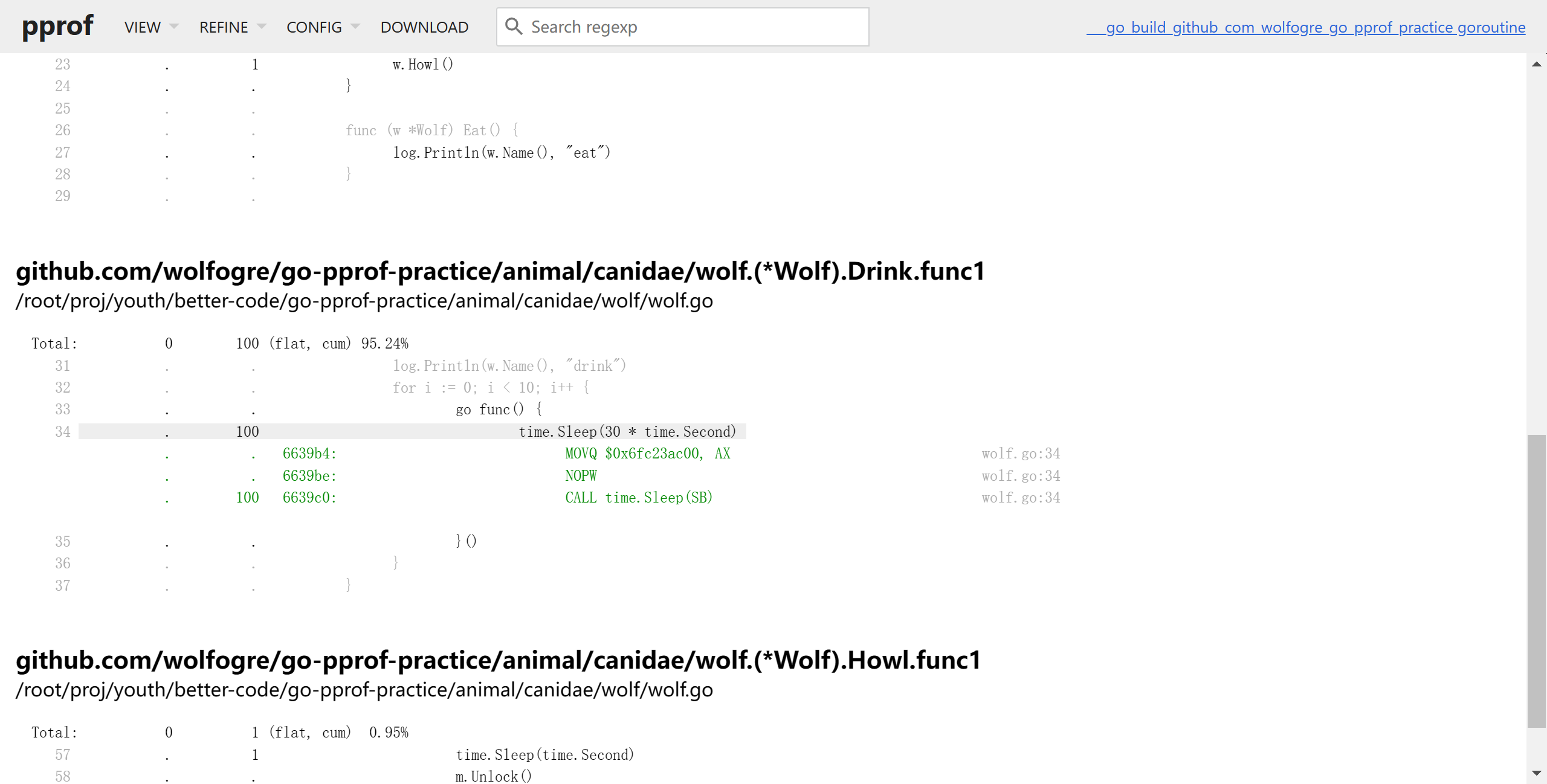
切回source,查找Wolf,发现代码申请了10个协程,每个运行30秒
mutex
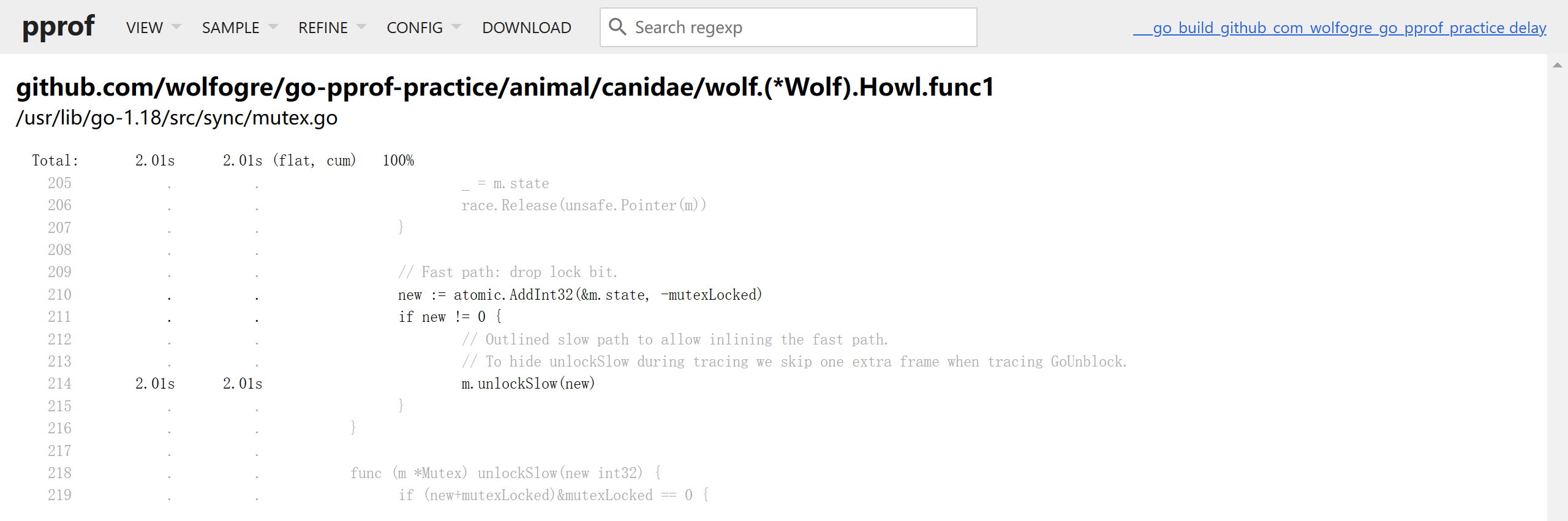
执行:go tool pprof -http=:8080 "http://localhost:6060/debug/pprof/mutex"
火焰视图:

source视图:
小结
pprof实战案例
pprof原理
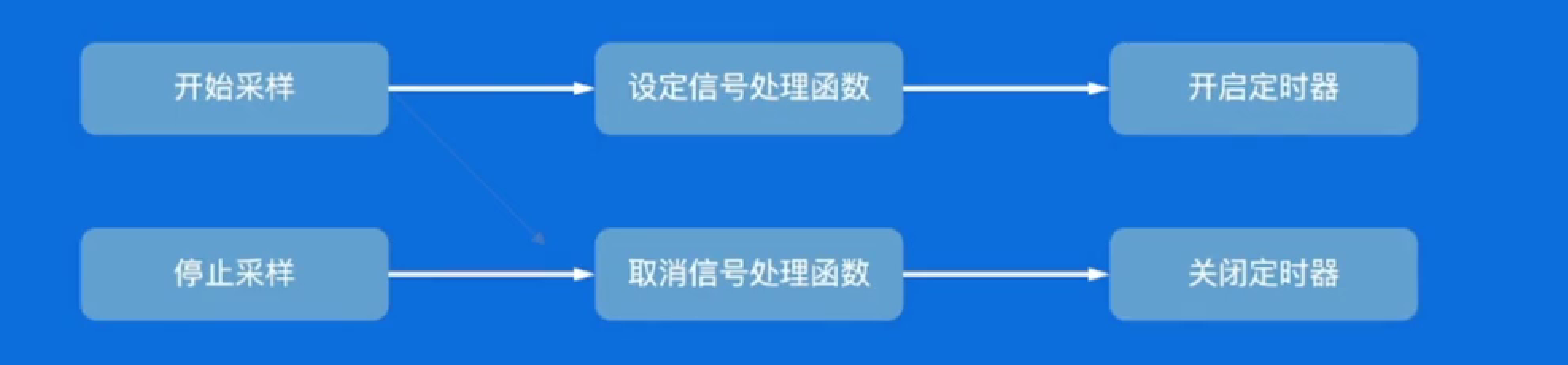
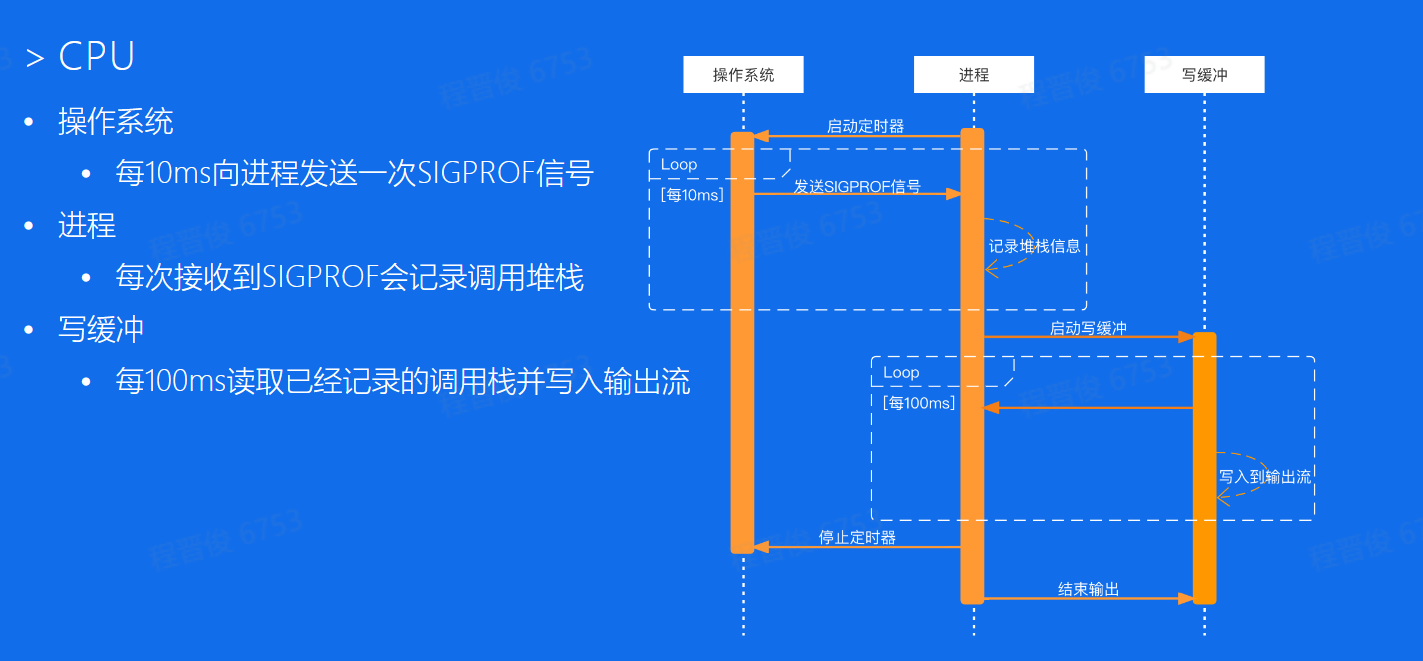
CPU采样原理:
- 采样函数调用占用的时间
- 采样率为100次/s
- 采样时间为手动开启或者结束
Heap采样:
- 采用程序通过内存分配器在堆上分配和释放的内存,记录分配/释放的大小和数量
- 每分配512KB记录一次,可修改(1为每次分配都记录)
- 采样时间:运行开始到开始采样时
- 采样指标:
alloc_space,alloc_objects,inuse_space,inuse_objects - 计算方式:
inuse = alloc - free
协程&线程
- goroutine记录所有用户发起的且在运行中的goroutine
- threadcreate记录程序创建的所有系统线程信息

Block阻塞&Mutex
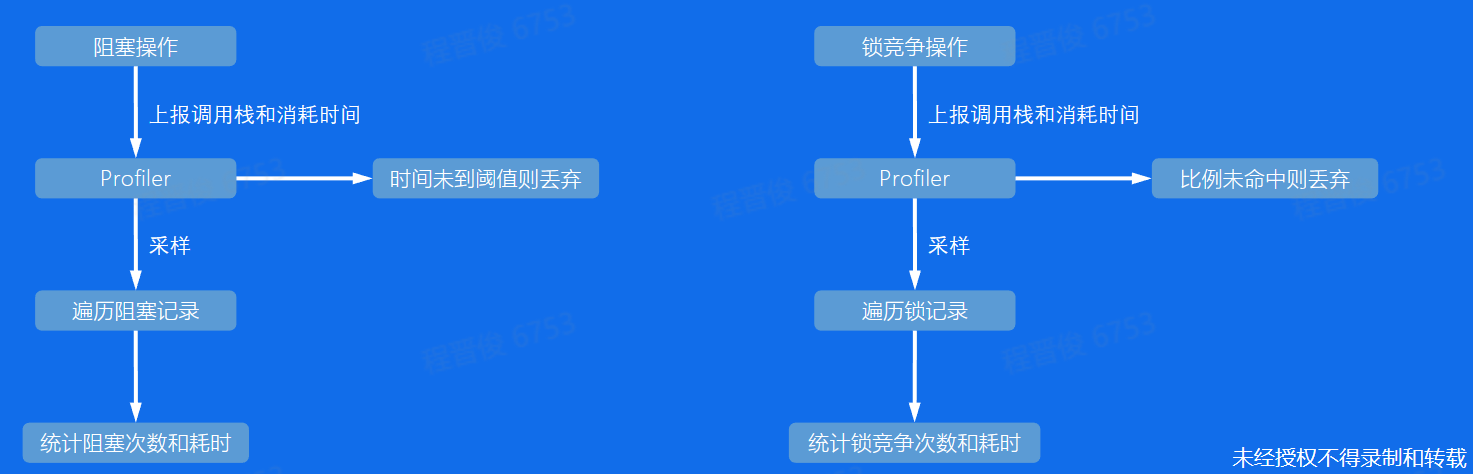
采样阻塞次数和耗时,采样阻塞时间超过阈值的,阈值设置为1表示每次都记录
锁竞争记录争抢锁的次数和时间消耗,
3 - 性能调优案例
基础服务优化
- 服务:能单独部署,承载一定功能的程序
- 依赖:Service A的功能实现依赖 Service B的响应结果,称为Service A 依赖Service B
- 调用链路:能支持一个接口请求的相关服
- 务集合及其相互之间的依赖关系
- 基础库:公共的工具包、中间件

业务优化流程
- 建立服务性能评估手段
- 分析性能数据,找到性能瓶颈
- 重点优化项改造
- 优化效果验证
建立服务性能评估手段
- 评估方式
- 单独 benchmark 不能满足复杂的逻辑分析
- 不同负载下性能表现差异
- 请求流量构造
- 同一个服务,不同请求参数覆盖逻辑不同,性能也不同
- 需要了解线上真实流量情况
- 压测范围
- 单机压测
- 集群压测(是不是有隐藏的条件没有注意到
- 性能数据采集
- 单机性能数据
- 集群数据
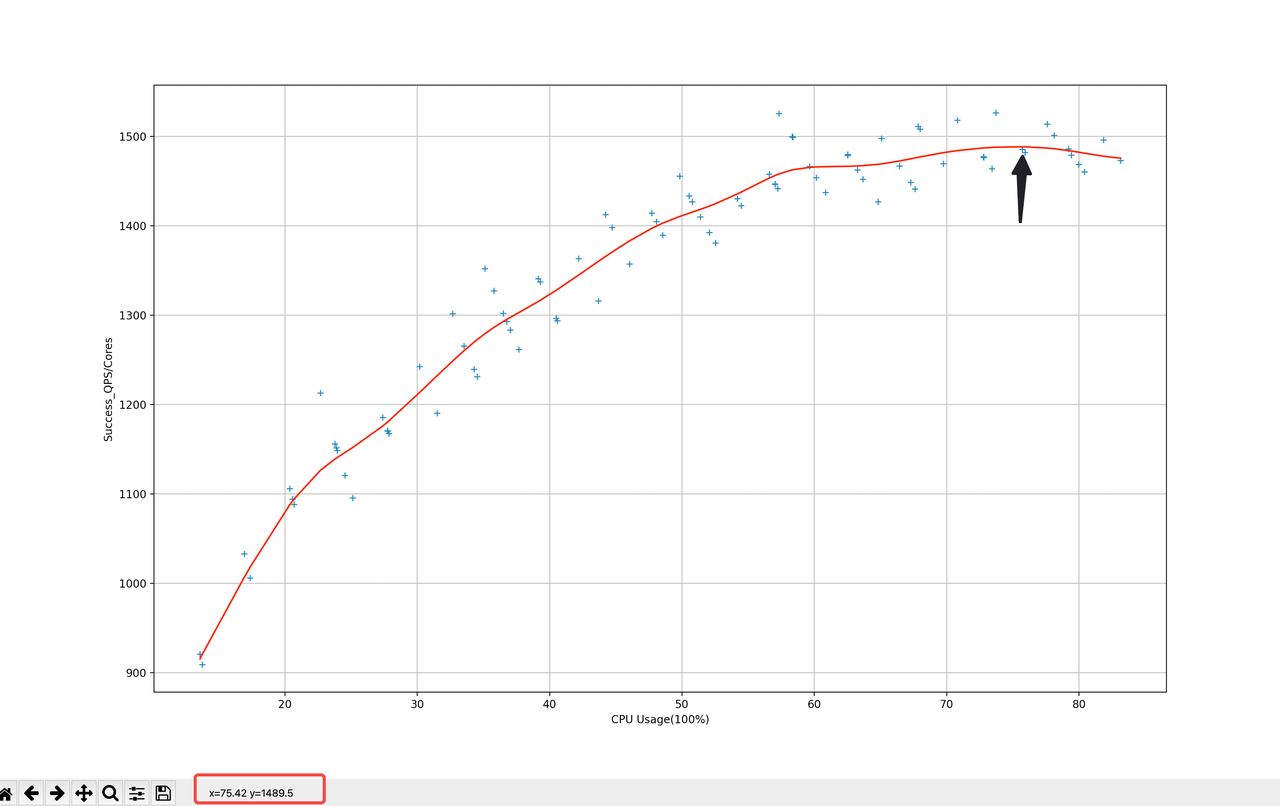
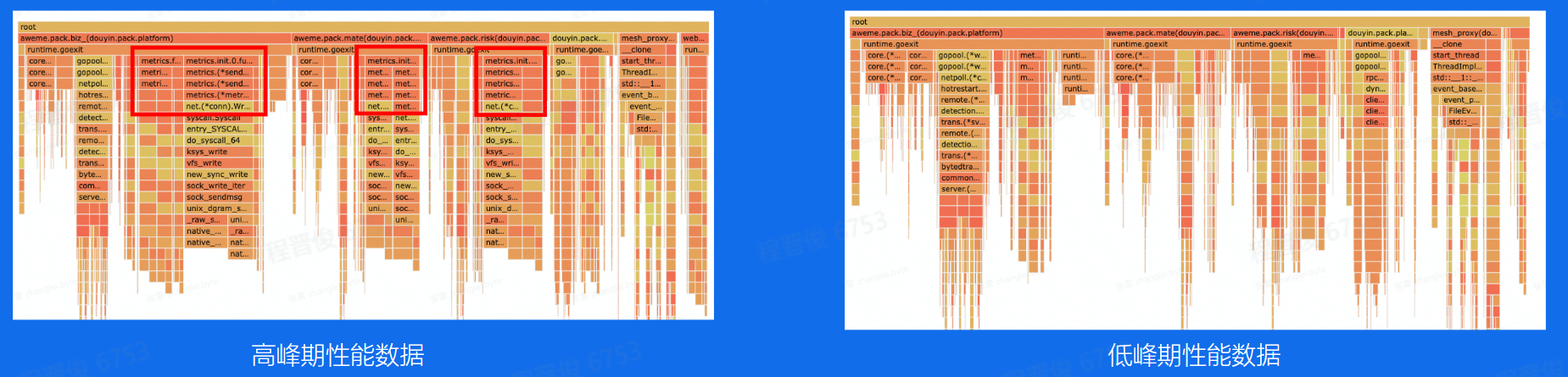
CPU增长情况,可以看出服务的最大负载。如果流量过大,可能需要考虑扩容
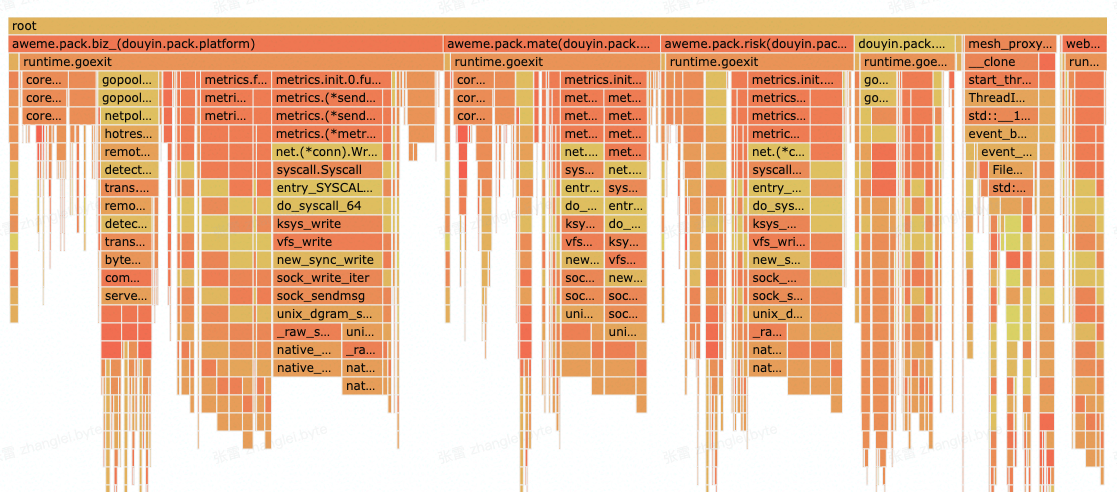
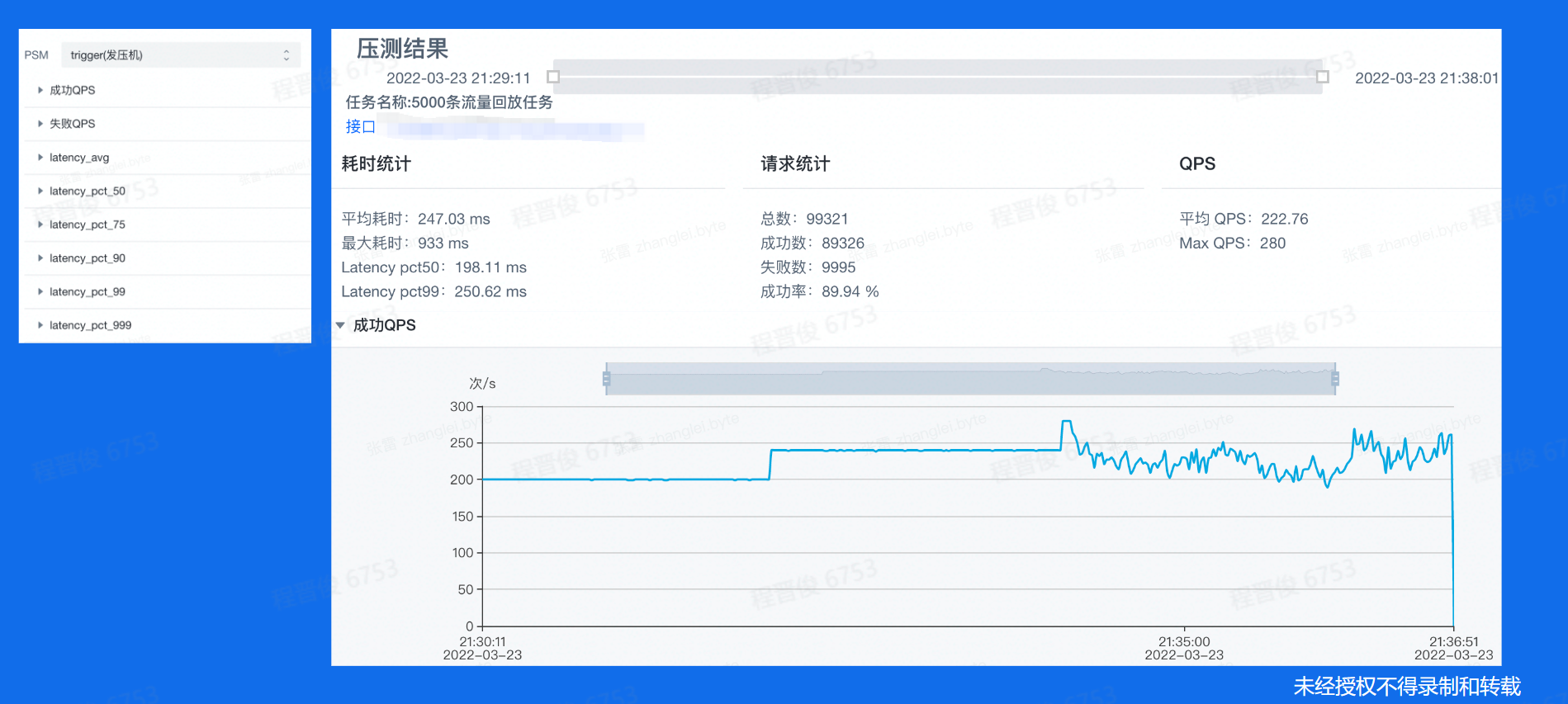
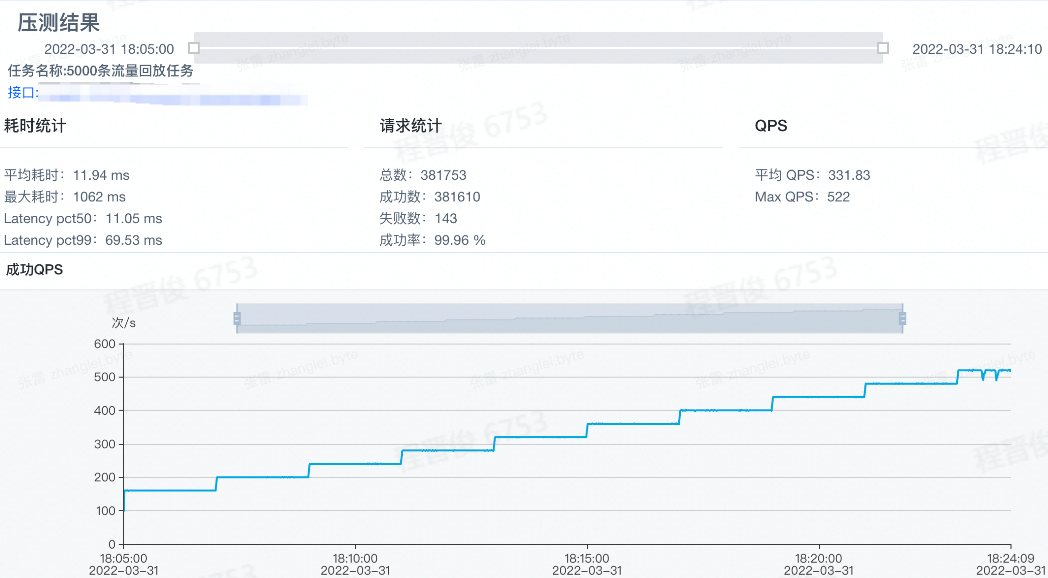
压测报告
分析性能数据
使用库不规范
json解析占用
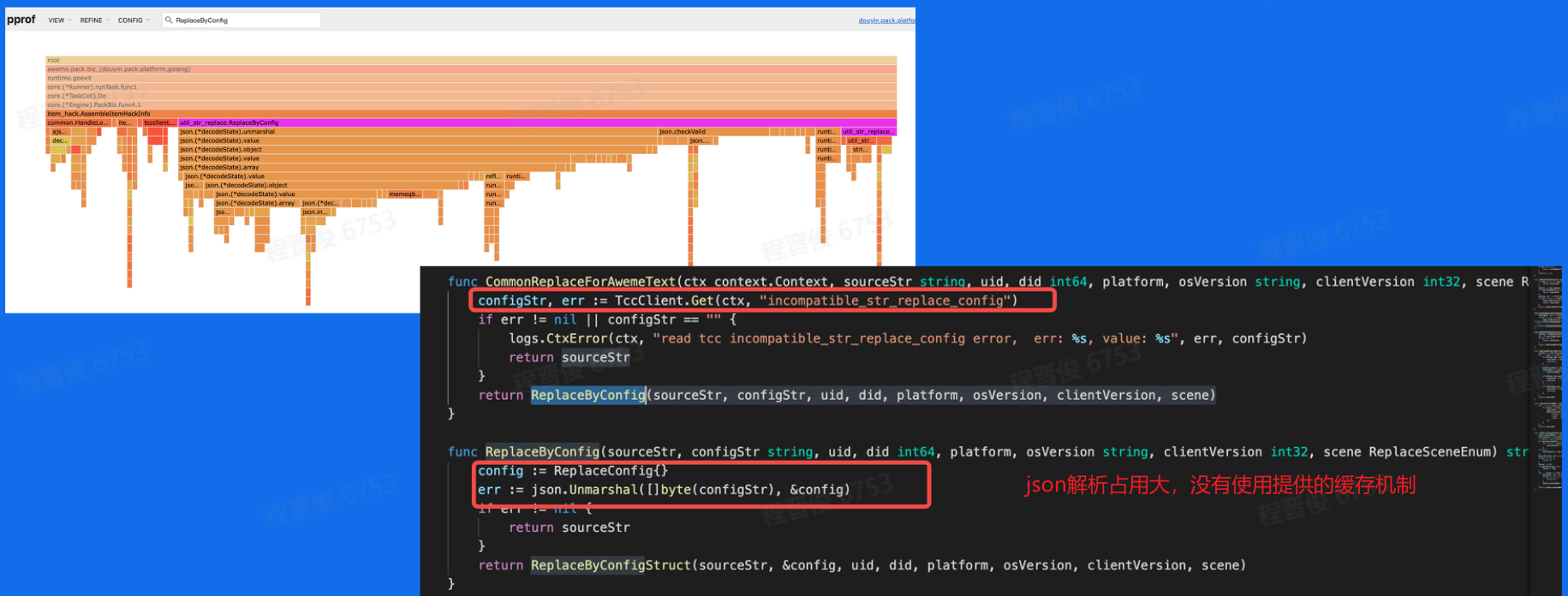
日志使用错误

高并发优化不足
监控数据使用同步请求上报,可改成异步上报
重点优化项改造
正确性是基础
查看响应数据的diff,判断改动对于正确性的影响

优化效果验证
重复压测验证
上线评估优化效果:
- 服务监控
- 逐步放量
- 收集性能数据
服务链路分析
规范上下游服务调用接口,明确场景需求
分析链路,通过服务流程优化提升服务性能
基础库优化
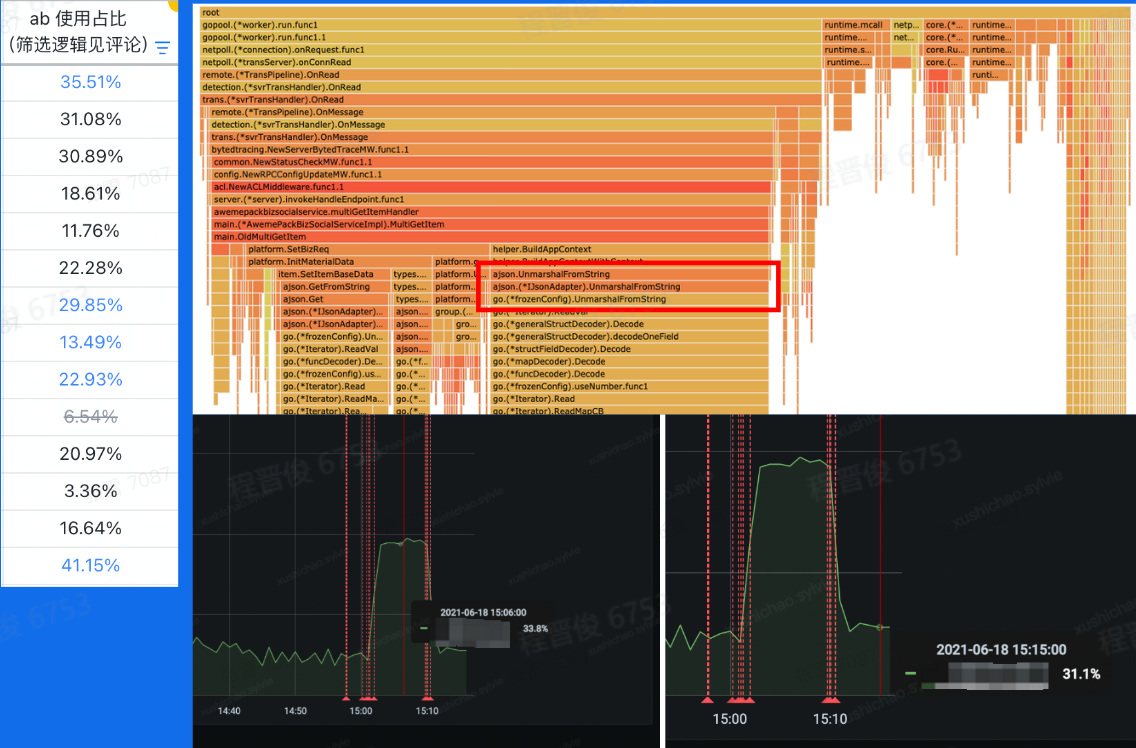
AB实验SDK优化
- 分析核心逻辑和性能瓶颈
- 设计完善改造方案
- 数据按需获取
- 数据序列化协议优化
- 内部压测验证
- 推广业务落地验证
Go语言优化
最有用最广的优化
编译器&运行时优化
- 优化内存分配规则
- 优化编译流程,生成更高效的程序
- 内部压测验证
- 推广业务服务落地验证
优点:
- 接入简单,只需要调整编译配置
- 通用性强
