03-内存管理

共享缓冲区
职责

组织机构
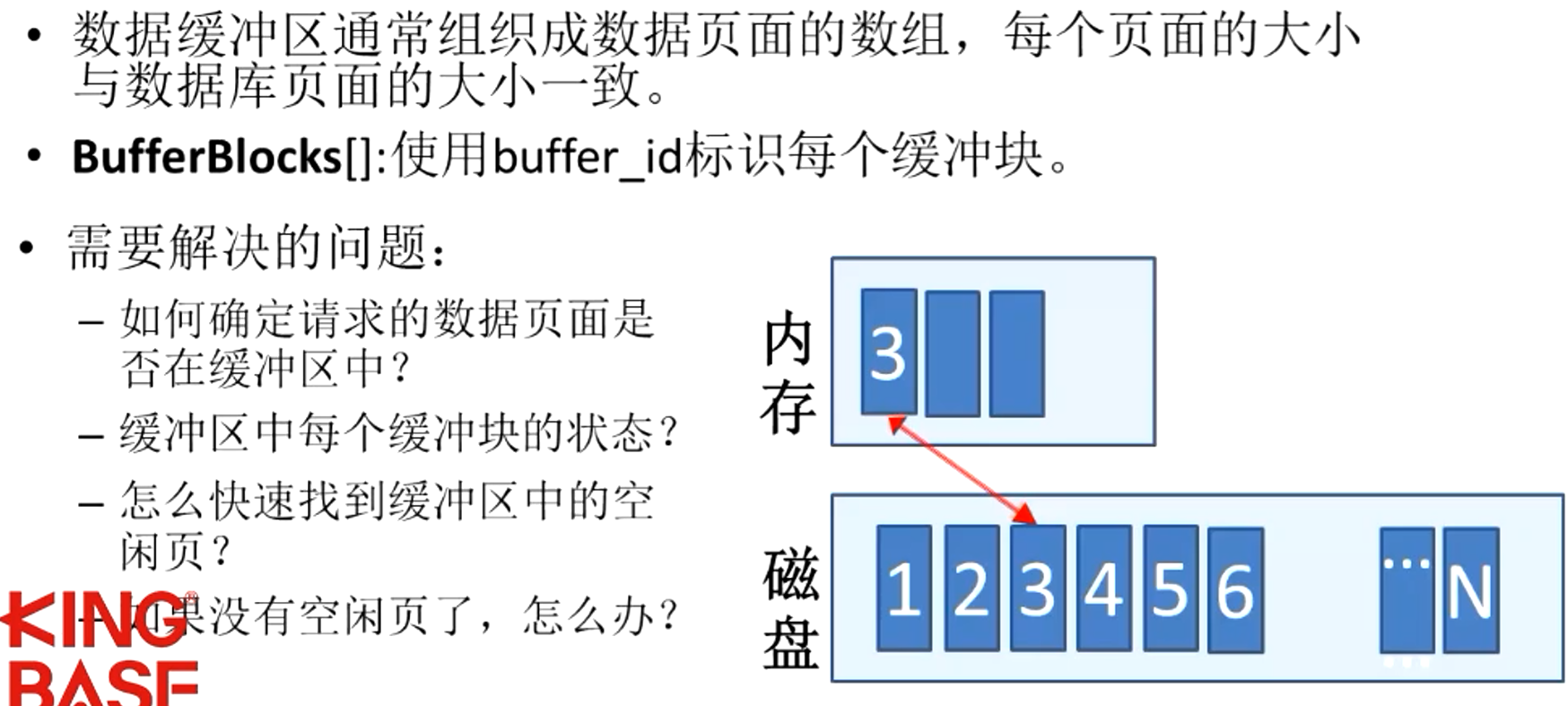
用哈希表


哪一个物理页面,哪一个缓冲区的页面(真节约)
组织机构

缓冲块上操作

-
Pin Buffer
- refcount有几个进程正在使用
- Pin操作:定在缓冲区里
-
Read/Write Buffer
- 读写缓冲块
- 缓冲区描述信息描述为脏页
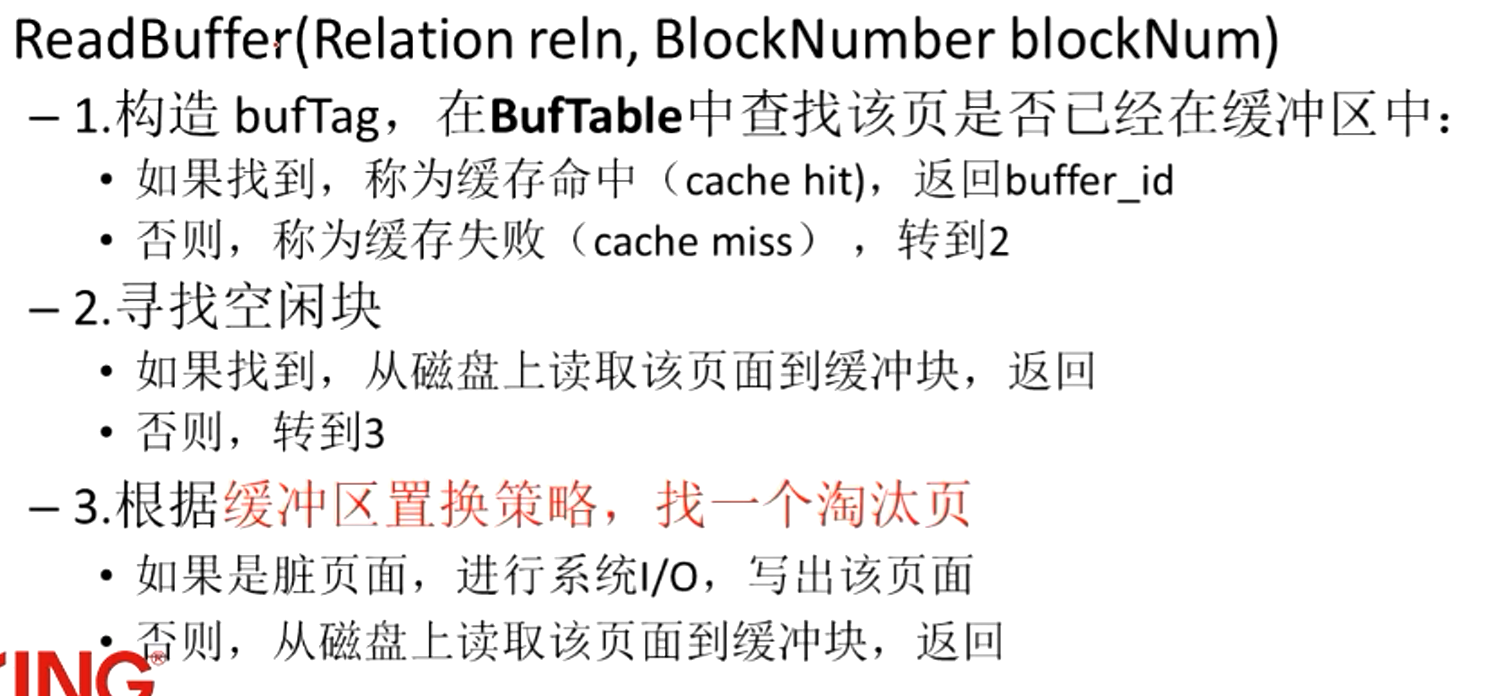
读取一个页面的过程
缓冲区置换策略

最常用缓冲区管理:轮转随机
LRU策略:常用的会再次用它
LRU策略

问题:
-
Index页在一个UPDATE Query中被读写多次,但是存储表的页 只被读写一次,然而,Index页面在用到的时候却没在内存;
-
我们希望index页能够常驻内存,并将一些表的页尽早的冒换 出去,留出更多的内存给index页。
LRU只考虑了使用时间,没有考虑使用频率
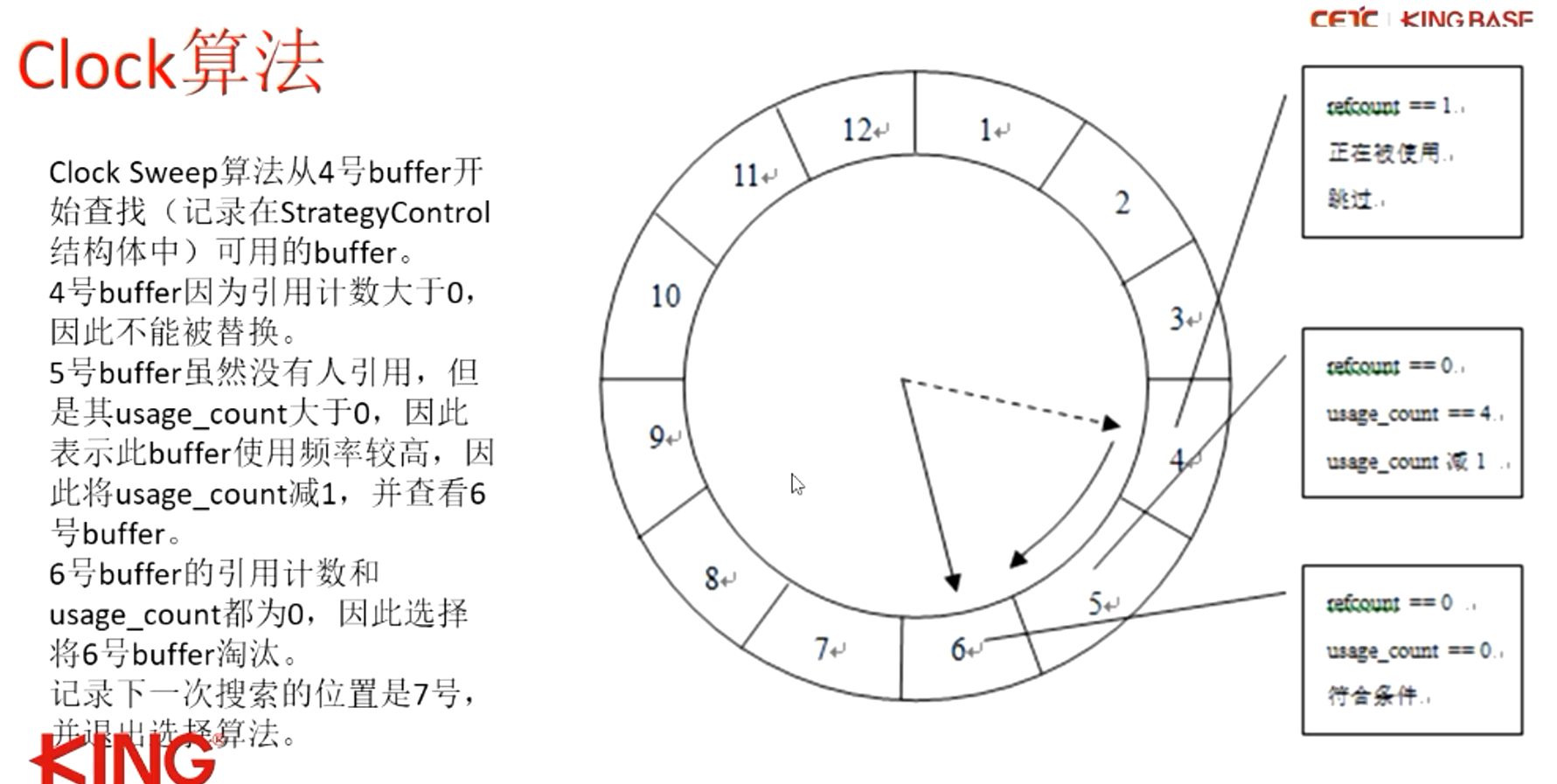
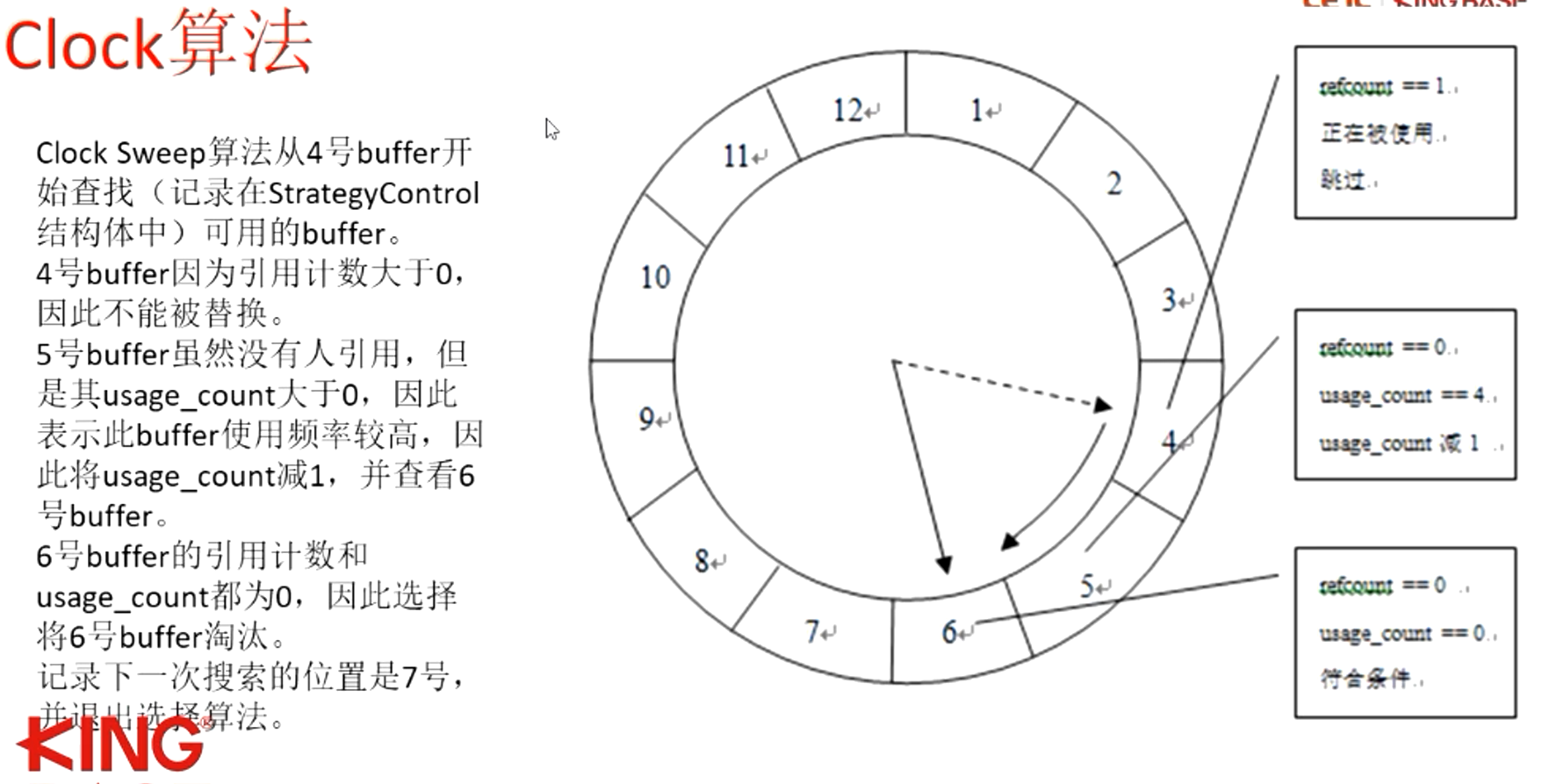
CLOCK算法
CLOCK算法:考虑时间和频率因素
两个计数:
- 引用计数(refcount)用于跟踪访问buffer的后台数量,防止错误的 将正在被使用的Buffer淘汰。当使用Buffer时,需要将其引用计数 (refcount)加1(PinBuffer)。当Buffer不再使用,需要将其引用 计数(refcount)减1(UnpinBuffer)。
- usage count用来标记Buffer被使用的次数,usage count值越大,说 明该Buffer经常被使用,不能作为被替换的对象;相反, usage_count值越小,说明经常不被使用,可以作为替换的对象。 只有当usage_count为0时,才可能作为替换的对象。
问题
- 缓冲区中共有5000个BufferPages,其中95%会被频繁引用, 但是当Seq Scan要扫描database所有页,于是出现所有厂商都 不希望出现的情况:“可能只被引用一次的页”将“频繁引 用的页”置换出去;=》I/O增加,出现长的I/o等待队列。
Buffer Ring

PostgreSQL的缓冲区管理

并发控制

门闩:轻量级的锁,只关心同时读写,不关心准确性















