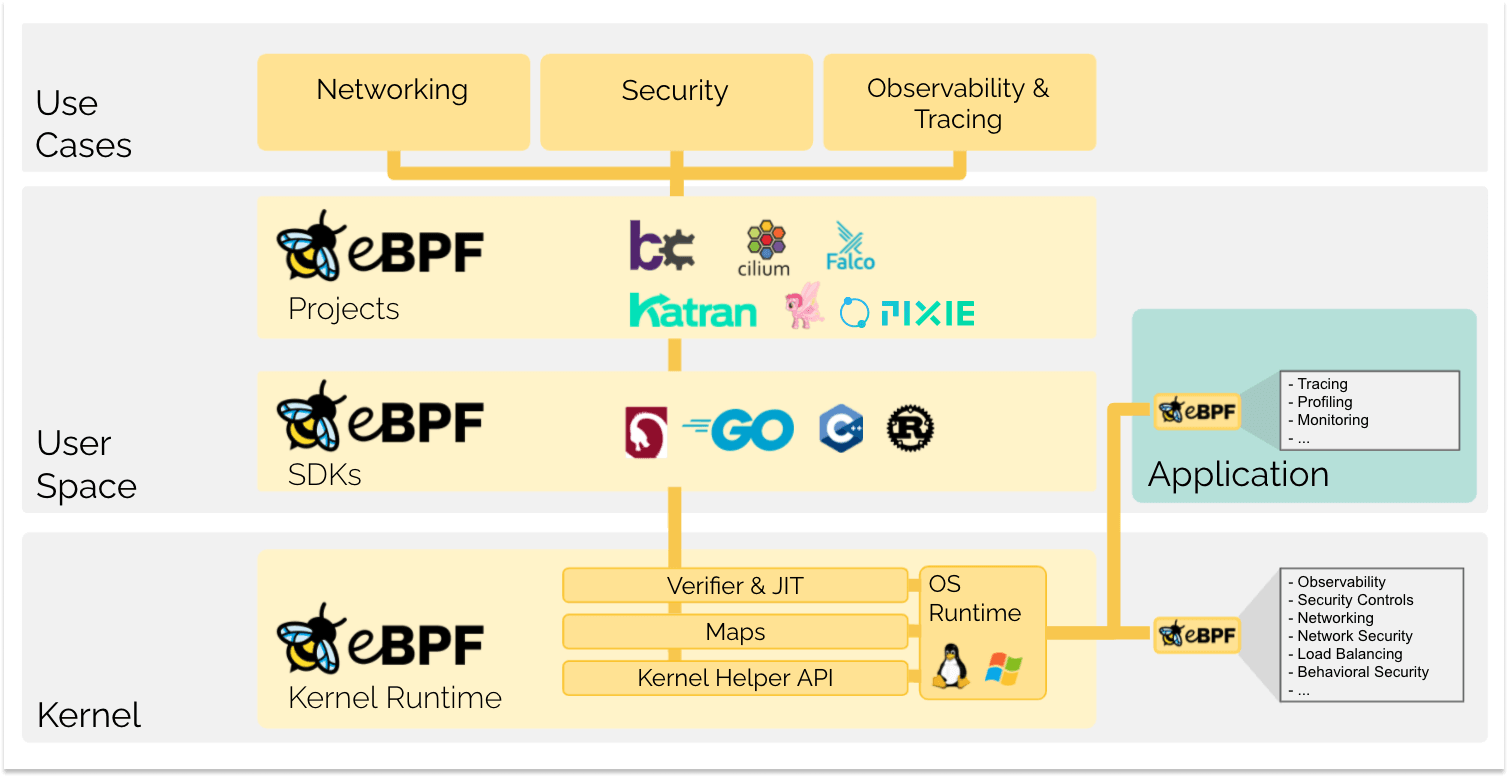
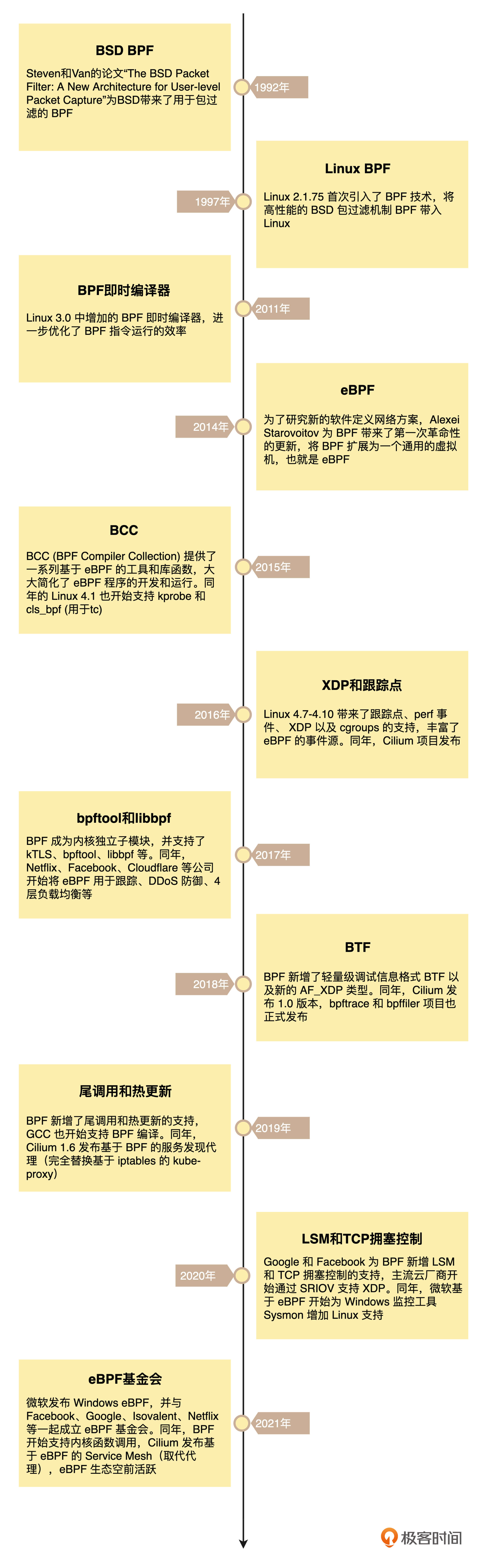
历史
最早起源于UCB数据包过滤器(Berkeley Packet Filter)1,是运行从用户空间传递的程序的内核虚拟机。用于在内核态过滤一部分数据,减少拷贝到用户空间的开销。

五年后,Linux 2.1.75 首次引入了 BPF 技术,Linux 3.0 中增加了 BPF 即时编译器。4.x 内核中将原本单一的数据包过滤事件逐步扩展到了内核态函数、用户态函数、跟踪点、性能事件(perf_events)以及安全控制等。从此,BPF 不再仅限于网络栈,而是作为内核的一个顶级子系统,并更名为eBPF。
ebpf发展脉络
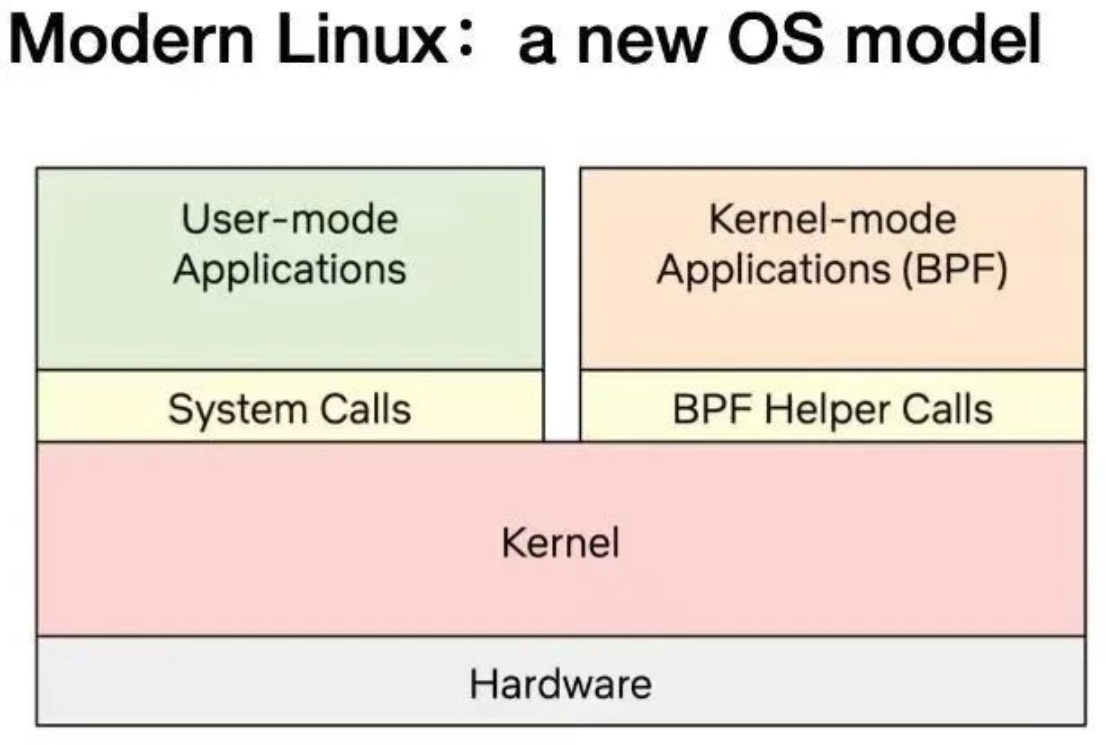
原理
工作方式
eBPF 程序并不像常规的线程那样,启动后就一直运行在那里,它需要事件触发后才会执行。这些事件包括系统调用、内核跟踪点、内核函数和用户态函数的调用退出、网络事件,等等。借助于强大的内核态插桩(kprobe)和用户态插桩(uprobe),eBPF 程序几乎可以在内核和应用的任意位置进行插桩。
验证
正因为其功能强大,确保安全和稳定一直都是 eBPF 的首要任务。
如下图2所示,我们向内核提交一个bpf程序后,内核会实现检查ebpf合法性,例如:
- 只有特权进程才可以执行 bpf 系统调用;
- BPF 程序不能包含无限循环;
- 安全:BPF 程序不能导致内核崩溃;
- BPF 程序必须在有限时间内完成。
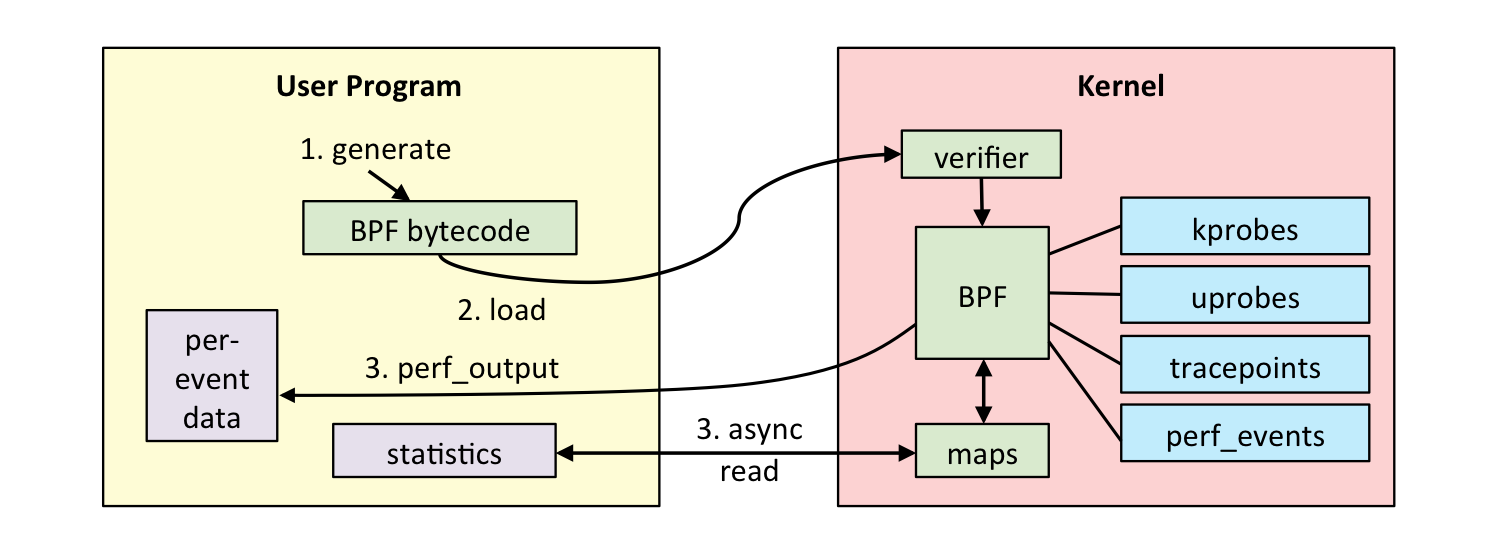
映射
BPF 程序可以利用 BPF 映射(map)进行存储,而用户程序通常也需要通过 BPF 映射同运行在内核中的 BPF 程序进行交互。如下图3所示,在性能观测中,BPF 程序收集内核运行状态存储在映射中,用户程序再从映射中读出这些状态。

以下为g可供映射的数据结构,可以选择为共享或CPU独享
- 哈希表
- 数组
- LRU (Least Recently Used)
- 环形缓冲区(Ring Buffer)
- 栈(Stack Trace)
- 最长前缀匹配 (Longest Prefix match)