线性判别分析
也叫Fisher判别分析。罗纳德·费希尔_百度百科
思想是:类内小,类间大。
从降维的角度出发,把数据全部投影到一维的坐标轴上,之后选定一个阈值来分类。
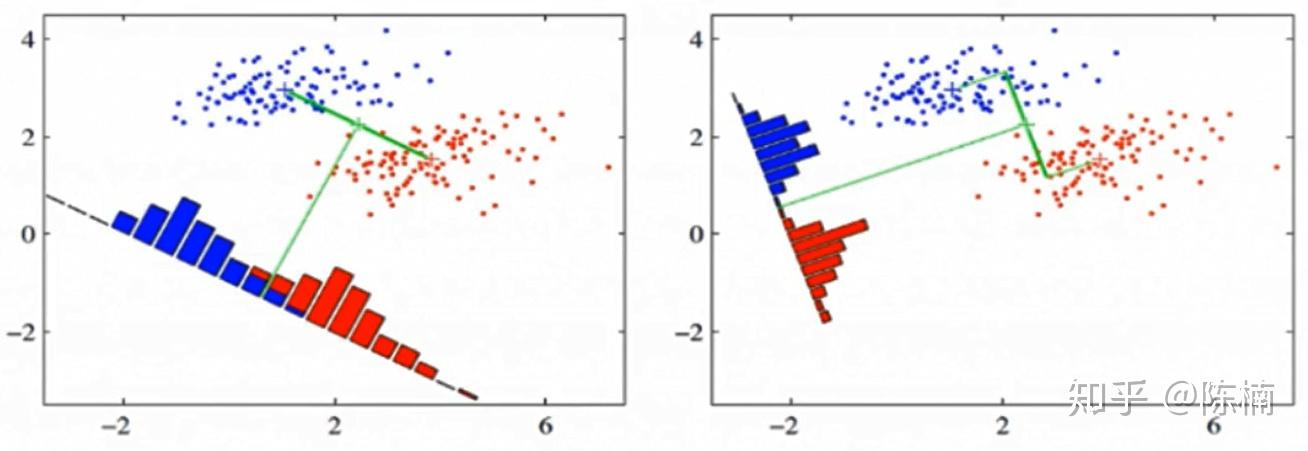
现在需要找一个最合适的投影方向,比如说上图中右边的更好。
这里指的就是最大化类间间隔,最小化类内方差。用计算机行话就是**“高内聚低耦合”**。
模型定义
首先是投影,我们假定原来的数据是向量 x,那么顺着 w 的方向投影就是标量z:
z=wT⋅x(=∣w∣⋅∣x∣cosθ)
投影的均值zˉ:
zˉ=N1wT⋅x
投影的方差Sz:
Sz=N1i=1∑N2(zi−zˉ)(zi−zˉ)T=N1i=1∑N2(wTxi−zˉ)(wTxi−zˉ)T
假设属于两类的试验样本数量分别是 N1和 N2,那么我们采用方差矩阵来表征每一个类内的总体分布,这里我们使用了协方差的定义,用 S 表示原数据的协方差:
C1:Varz[C1]=N11i=1∑N1(zi−zc1)(zi−zc1)T=N11i=1∑N1(wTxi−N11j=1∑N1wTxj)(wTxi−N11j=1∑N1wTxj)T=wTN11i=1∑N1(xi−xc1)(xi−xc1)Tw=wTS1w
C2:Varz[C2]=N21i=1∑N2(zi−zc2)(zi−zc2)T=wTS2w
所以类内距离可以记为方差的和:
Varz[C1]+Varz[C2]=wT(S1+S2)w
对于类间距离,我们可以用两类的均值表示这个距离:
(zc1−zc2)2=(N11i=1∑N1wTxi−N21i=1∑N2wTxi)2=(wT(xc1−xc2))2=wT(xc1−xc2)(xc1−xc2)Tw
综合这两点,由于协方差是一个矩阵,于是我们用将这两个值相除来得到我们的损失函数,并最大化这个值:
w^=wargmaxJ(w)=wargmaxVarz[C1]+Varz[C2](zc1−zc2)2=wargmaxwT(S1+S2)wwT(xc1−xc2)(xc1−xc2)Tw=wargmaxwTSwwwTSbw
这里
-
Sb(Between Class)表示类间方差
-
Sw(Within Class)表示类内方差
模型求解
这样,我们就把损失函数和原数据集以及参数结合起来了。
下面对这个损失函数求偏导,注意我们其实对 w 的绝对值没有任何要求,只对方向有要求,因此只要一个方程就可以求解了:
∂w∂J(w)=2Sbw(wTSww)−1−2wTSbw(wTSww)−2Sww=0⟹Sbw(wTSww)=(wTSbw)Sww⟹w∝Sw−1Sbw=Sw−1(xc1−xc2)(xc1−xc2)Tw∝Sw−1(xc1−xc2)
于是 Sw−1(xc1−xc2) 就是我们需要寻找的方向。最后可以归一化求得单位的 w 值。